Top 30 AI Agent Products: Three Emerging Trends
 02/28 2026
02/28 2026
 478
478
By 2026, AI agents have become extremely popular.
Claude Code, ChatGPT Agent, Manus, along with numerous enterprise-level workflow platforms from leading companies, all boast capabilities to “replace human workers” and “create trillion-dollar value.” McKinsey’s report further stokes the flames: 62% of enterprises are currently testing AI agents.
However, beyond the hype, the critical question remains: How much progress have AI agents actually made in real-world work scenarios?
Recently, research teams from MIT, Harvard, Stanford, and other institutions released the “2025 AI Agent Index.”
These scholars have made a significant contribution:
They conducted a systematic analysis of the 30 most representative agent systems available in the market. They designed 45 dimensions to thoroughly evaluate these products in terms of technical details, deployment status, design architectures, tool usage, and safety mechanisms. From this analysis, they identified the three most crucial insights about AI agents today.
Through this report, we can gain a clearer understanding of the current state of AI agent development.
/ 01 / Product Forms Converge in Three Key Directions
Most AI agent products were launched between 2024 and 2025.
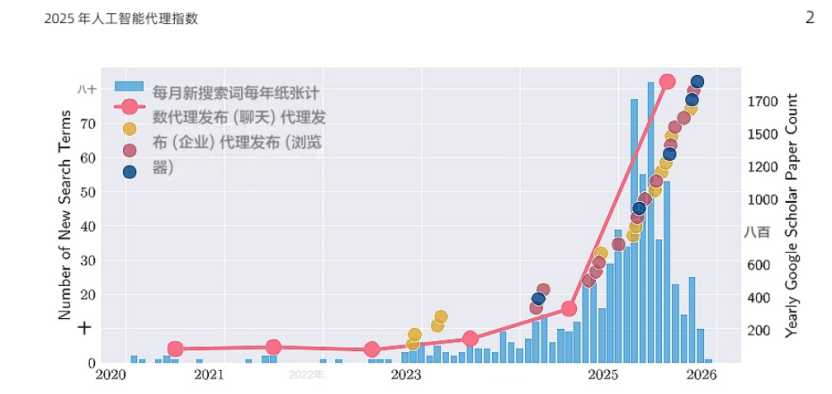
(The blue bar chart represents Google’s new search terms related to agent-based AI products, while the red line indicates the number of academic papers published on Google Scholar containing the keywords “AI agent” or “agent-based AI.”)
From a product form perspective, AI agents primarily converge in three directions:
Chat-based agents (12): These agents use dialogue as the primary interface and are equipped with various toolkits.
Enterprise automation platforms (13): These platforms focus on automating B2B workflows and have become a mainstream form that rivals chat interfaces.
Browser/GUI-based agents (5): These agents directly take over screen interactions, simulating human clicks and inputs, similar to previous mobile assistants like Doubao.
Enterprise workflow platforms have emerged as a mainstream form on par with chat interfaces. Among them, GUI-based agents developed in China are more inclined to integrate phone and computer operation capabilities (3 out of 5 possess dual capabilities), offering higher functional integration.
In terms of application scenarios, the top three examples are: information research and integration (12), cross-departmental workflow automation (11), and browser operations like form filling and reservations (7).
Regarding foundational models, aside from “cutting-edge labs” like Anthropic, Google, OpenAI, and some Chinese vendors using self-developed models, most agents heavily rely on GPT, Claude, or Gemini series.
Although “model openness” has become an industry trend, the situation with agent products is entirely different.
Among the 30 agents, 23 are fully closed-source. Only 7 have open-sourced their agent frameworks or tool layers, including Alibaba’s MobileAgent, Browser Use, TARS, Gemini CLI, n8n, OpenAI Codex, and WRITER.
While ecosystems are becoming more open, commercial products remain predominantly closed. This represents a typical “open framework, closed product” structure.
/ 02 / From Action Space to Autonomy, AI Agents Are Diversifying
While all are called “agents,” these 30 products vary greatly in functionality.
A core distinction lies in their action spaces.
Enterprise workflow agents primarily execute operations through system connectors like CRMs and databases (8/30). They function more like automated execution nodes within enterprise processes.
Command-line interface (CLI) agents directly manipulate file systems and terminal commands (4/30), with capabilities more suited to engineering environments.
Browser agents operate most intuitively: clicking, inputting, and navigating web pages (5/30), directly “replacing humans” in interface operations.
Notably, enterprise agents’ action spaces are usually strictly limited, with priority given to tool permissions and usage safeguards. In other words, the closer to real business systems, the stricter the controls.
Agent products also exhibit different choices in user interfaces.
In enterprise scenarios, canvas-based orchestration interfaces have become standard. 8/13 enterprise platforms adopt visual workflow combination interfaces, allowing users to configure triggers, actions, and safeguard rules.
In consumer scenarios, chat interfaces remain the dominant entry point (14/30). This means design emphasizes process construction, while usage emphasizes natural language interaction.
Most critically, different types of agents show clear stratification in “autonomy.”
The most common remains “turn-based assistants.” Products like Claude, Gemini, and ChatGPT employ low-to-moderate autonomy modes (L1–L3): after executing a set of actions, they await the user’s next instruction.
This structure remains fundamentally human-centric, with models merely extending operational chains.
However, autonomy differences within the same product can be extreme. For example, the gap between “general chat” and “in-depth research” functions approaches two different paradigms: the former merely generates responses, while the latter can autonomously plan task paths to some extent.
Browser agents represent the other extreme. They typically reach L4–L5 autonomy, significantly higher. Once receiving instructions, they complete the entire execution process independently, with virtually no real-time intervention space. Users relinquish control the moment they submit the task.
Enterprise-grade agents exhibit a more complex structure: low autonomy during design, high autonomy during operation.
Simply put, during design, users configure triggers, workflows, and safeguard rules through visual canvases, with some platforms offering AI assistance (L1–L2).
But after deployment, agents are usually triggered automatically by events like emails or database updates, requiring no human participation during runtime, entering L3–L5 states.
This means autonomy doesn’t grow linearly but rather “switches stages.”
/ 03 / As Autonomy Strengthens, Accountability Boundaries Blur
From the interface layer, MCP has become the dominant standard in the agent ecosystem. 20 out of 30 systems support this protocol, indicating convergence in “how tools are accessed.” Among enterprise platforms, some are beginning to support agent-to-agent protocols (A2A), but this remains in early stages.
Despite protocol-layer convergence, identity layers are diverging.
Most agents default to not disclosing their AI identity to end-users or third parties. 21/30 lack recorded default disclosure behaviors, with only a minority supporting generated content watermarks.
In other words, enterprise platforms often delegate disclosure responsibilities to clients—whether to inform users “you are interacting with AI” isn’t the platform’s burden.
At the technical identification level, the situation is more complex.
Most browser agents typically ignore robots.txt files, operating directly as “representing users.”
Enterprises argue agents shouldn’t be treated as traditional crawlers, but this logic is sparking legal controversies.
The trend of agents bypassing network restrictions is altering control structures—shifting from content hosts to agent operators.
Currently, ChatGPT Agent is the only system using encrypted request signatures. Most agents lack verifiable identity mechanisms.
As more tasks are delegated to agents, “who is acting” becomes increasingly critical. Meanwhile, transferring disclosure responsibilities to operators raises a question: do end-users truly know they’re interacting with AI?
Simultaneously, when builders shift safety responsibilities to users, accountability boundaries blur. A more practical question emerges: to what extent can humans still control agents once they begin executing tasks?
Among these 30 agent products, most design approval and supervision mechanisms, but approaches vary.
For example, developer or CLI-type agents typically require explicit confirmation for high-sensitivity operations like file modifications or command executions; browser agents place more control nodes at identity verification and payment stages.
Some products even offer “real-time monitoring modes,” allowing users to observe execution during critical steps.
But upon closer inspection, transparency varies greatly between products.
A minority of agents display complete action trajectories and reasoning processes, letting users clearly see how they make decisions and which tools they invoke; more systems provide only generalized explanations, leaving almost no traceable records during execution.
For many enterprise platforms, outsiders can’t even confirm whether real-time monitoring exists during individual runs.
This means control mechanisms “exist” but unevenly; supervision logic is “visible” but not standardized. As agent capabilities improve, human visibility into execution processes hasn’t increased proportionally.
/ 04 / Conclusion
This index records 30 agent systems across 1,350 dimensions, but more importantly, it reveals three structural trends:
First, safety disclosures are highly uneven.
Only a minority of agents publish systematic cards detailing their architectures. Most systems either disclose only foundational model information or emphasize compliance certifications. A clear asymmetry exists between capability benchmarks and safety assessments.
When agent risks increasingly stem from planning capabilities and tool invocations rather than just model outputs, relying solely on model-level documentation is insufficient.
Second, foundational models are highly concentrated.
Nearly all agents rely on GPT, Claude, or Gemini. This concentration in model supply brings efficiency and evaluation convenience but also implies single-point risks. Pricing adjustments, service disruptions, or security vulnerabilities could cascade to downstream systems.
Risk management must therefore extend beyond agent deployers to upstream model providers.
Third, accountability chains are fragmented.
Agent systems often form multi-layer dependency chains: foundational models, orchestration layers, building platforms, deployers, and end-users. No single entity holds responsibility for complete behaviors.
Under this distributed architecture, relying solely on model documentation for safety judgments easily creates false assurances.
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







