Anthropic, Accused of Tech Theft by Chinese Companies, Revealed as North America's Biggest 'Data Thief?'
 02/28 2026
02/28 2026
 515
515
Wiping its mouth after stealing copyrighted content, it shouts, 'Go catch the thief!'
An annual spectacle of 'the thief crying thief' unfolds on the stage of the U.S.-China AI competition.
On February 23, a news story broken by TechCrunch instantly ignited global AI discourse.
The report claimed that Anthropic, a star startup branded as a champion of 'AI safety,' publicly accused three leading Chinese AI large model companies—DeepSeek, Moonshot AI, and MiniMax—of systematically defrauding its Claude model to train and optimize their own models.
According to Anthropic's data, the scale of this 'industrial-grade' theft was staggering: the three companies collectively created over 24,000 fake accounts, engaging in approximately 16 million interactions with the Claude model. Anthropic alleged that these actions aimed to systematically extract Claude's core capabilities—including reasoning, programming, and tool usage—through 'distillation,' thereby taking a shortcut to enhance their own models' performance.
This accusation precisely targeted the pain point of U.S.-China AI competition. Anthropic labeled itself a 'victim of intellectual property theft' while conveniently branding its Chinese rivals as 'copycats' in the court of public opinion.
Ironically, the tech circle's memory hasn't faded that quickly. Just last year, this self-proclaimed 'industry benchmark' accuser had only just paid $1.5 billion in 'hush money' to settle copyright lawsuits after illegally using pirated books to train its models. Anthropic's move smacks of 'whitewashing itself before reporting former peers.'
After the incident escalated, Tesla CEO Elon Musk swiftly fired off his classic 'soul-searching question' on social platform X: 'How dare they (Chinese companies) steal what Anthropic stole from human programmers?' He added, 'We (xAI) don’t act as smug, sanctimonious, and hypocritical as Anthropic.'

When a former 'master thief' begins accusing others of 'theft,' we must ask: Is this a righteous act to uphold intellectual property, or a PR strategy by a 'convict' trying to mask its own 'original sin' by attacking rivals amid fierce competitive anxiety?
Is Anthropic, Silicon Valley's AI darling, a defender of technological innovation—or North America's biggest 'data thief'?
01
Did Anthropic, the 'Thief Hunter,' Forget Its Own Origins?
Before delving into Anthropic's 'dark history,' we must first clarify the core of this accusation: 'distillation.'
In AI, 'distillation' is a common technique for model compression and knowledge transfer. Simply put, it involves training a smaller, lighter 'student model' using outputs from a larger, stronger 'teacher model.'
By mimicking the 'teacher model's' responses to vast questions, the 'student model' learns its powerful logical reasoning and knowledge organization abilities, rapidly closing the performance gap.
Does this constitute 'theft'? It remains a legally and ethically contentious gray area.
Rewind to early 2025, over a year ago, when DeepSeek's R1 model, developed at minimal cost, swept the globe and sent Silicon Valley into panic. OpenAI then played Anthropic's current role, claiming to have caught DeepSeek 'distilling' its advanced models, sparking a heated public debate.
From a strict technical standpoint, this doesn't involve directly copying model code or weight parameters. It resembles an apprentice observing a master's painting, learning style and techniques through imitation rather than stealing the artwork itself. Many open-source models and research projects explore distillation to achieve higher performance at lower costs.
Commercially, however, large model companies uniformly prohibit such behavior in their user terms of service. They invest billions—even over $10 billion—in R&D and computational resources, treating model outputs (or API calls) as core commercial assets.
Allowing competitors unlimited 'distillation' of their models would tacitly permit rivals to replicate their core competitiveness at minimal cost—clearly unacceptable.
Thus, Anthropic's accusation holds merit regarding 'violation of terms of service.' However, escalating it to 'technology theft' or even 'commercial espionage' risks exaggerating a commercial dispute.
After all, if APIs are publicly available, using their outputs for research or training is far more complex in nature than hacking servers or stealing source code.
The crux of this debate lies in redefining knowledge boundaries in the AI era: Are a model's outputs protected intellectual property, or public knowledge to be learned and adapted? Until this question is answered definitively, Anthropic's loud accusations lack unshakable legal and moral grounding.
Moreover, this 'plaintiff' employed far more brutal and direct methods than 'distillation' when acquiring knowledge for model training.
02
$1.5 Billion Settlement Exposes AI's 'Original Sin'
Before wielding moral authority against peers, this self-appointed 'AI copyright police' had just paid a staggering 'fine' for its own 'theft.'
The timeline rewinds to 2025, when Anthropic faced a legal crisis dubbed 'Bartz v. Anthropic.' Initiated by multiple U.S. authors, the lawsuit accused Anthropic of illegally using millions of copyrighted books to train its Claude series models.
These books weren't legally purchased but directly downloaded en masse from notorious piracy sites like LibGen, Sci-Hub mirrors (e.g., PiLiMi), etc.
This has long been an open secret in the AI industry: to obtain high-quality, structured training corpora, many companies turn to these pirated libraries amassing nearly all human-published knowledge.
In court, Anthropic attempted to defend itself using the 'fair use' doctrine. They argued that using book texts for AI training constituted 'transformative use,' aimed not at replacing the books but at extracting statistical patterns to build language capabilities, and thus didn't infringe copyrights.
However, the presiding judge didn't fully accept this argument. The court's ruling drew a critical red line on the legality of AI training data.
It held that if data is legally acquired (e.g., purchasing and scanning books), its use in AI training might be considered fair use. But obtaining data through illegal means (i.e., downloading from piracy sites) from the outset constitutes copyright infringement, rendering any subsequent use ineligible for 'fair use' exemption.
In short, the court ruled: AI's 'alchemy' cannot rely on stolen raw materials.
This judgment directly found Anthropic liable. Estimates suggested that if all infringement claims held, with statutory damages up to $150,000 per work, the potential penalties could reach astronomical figures. To avoid bankruptcy, Anthropic ultimately compromised.
In September 2025, both sides reached a settlement. Anthropic agreed to pay authors and publishers $1.5 billion in compensation. This sum covered approximately 500,000 works, averaging roughly $3,000 per book's 'ransom.' As part of the settlement, Anthropic was also required to destroy all training data obtained through piracy.
This case marked not only the largest copyright settlement in AI history but also a landmark event. It permanently branded Anthropic—a company long positioning itself as a leader in 'AI safety and ethics'—as a 'data thief.' To build Claude's intelligence, they pirated entire libraries.
03
A Farce of 'The Pot Calling the Kettle Black'
Wiping its mouth after feasting on copyright dividend ( dividend : dividends/profits, kept as-is for contextual meaning), it indignantly accuses others of 'freeloading.' The absurdity of this Silicon Valley drama has peaked.
When Anthropic accuses Chinese companies of 'stealing' its model capabilities, it conveniently forgets that Claude's own abilities were built substantially on 'stolen' book knowledge. This makes Anthropic's accusations particularly laughable and hypocritical.
Musk's mockery, though harsh, pinpointed the core contradiction: a company built on 'theft' now posing as a defender of intellectual property is a masterstroke of black humor.
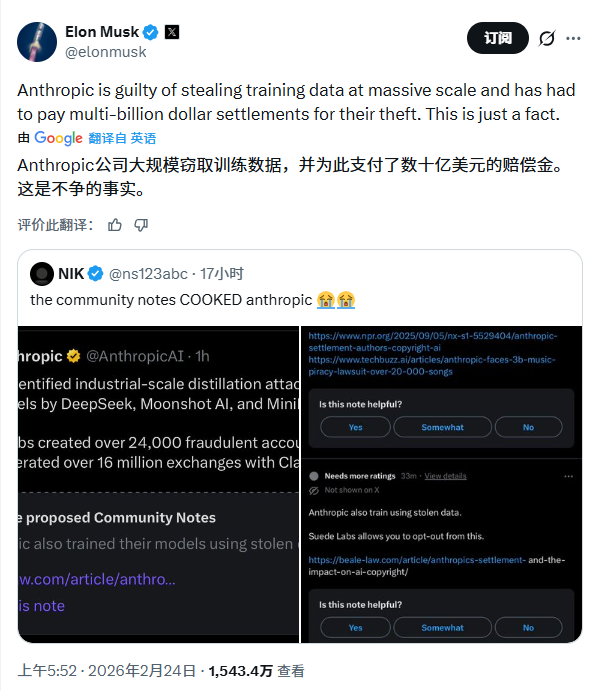
Gergely Orosz, a renowned programmer and tech blogger, echoed this sentiment: 'Sorry, but Anthropic can’t have it both ways... Remember how Claude was trained? With copyrighted books, until sued and then paid the copyright holders.'
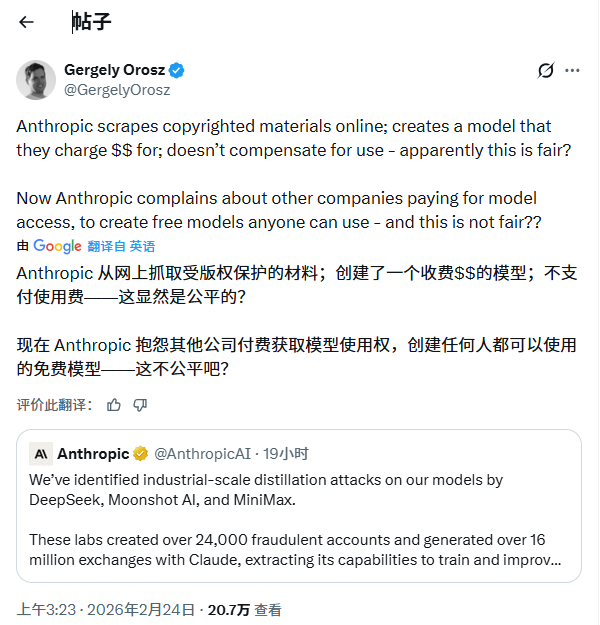
Programmer communities and online forums buzzed with similar skepticism. One Reddit user bluntly stated: 'Anthropic pirated millions of books and now lectures on responsibility and compliance... If you believe their narrative, you’re naive.'
Facing overwhelming public backlash, Anthropic's defenses rang hollow. They claimed their training data included legally sourced materials and that the $1.5 billion settlement had 'resolved' historical issues.
This logic fails to convince. Paying fines or settlements compensates for past infringements legally but doesn't erase the moral wrongdoing.
It’s like a thief returning stolen goods and paying a fine, then indignantly accusing others of theft—unconvincing from any angle.
The deeper issue lies in whether Anthropic's $1.5 billion payment represented genuine remorse, a forced 'indulgence,' or a calculated 'cost' for acquiring massive high-quality data. Given its current moral posturing, the latter seems more plausible.
They appear to believe that 'settling' past wrongs financially grants them moral rebirth, entitling them to judge others from a high horse.
However, the internet has memory.
Zooming out to the entire AI industry, Anthropic's case reveals a broader dilemma: nearly all leading large model companies rose by 'wildly' scraping vast internet data, inevitably including copyrighted content. This is the industry's 'original sin.'
From OpenAI to Google to Anthropic, their models' astonishing intelligence stems from 'reading' nearly all human-published texts and images. Whether they obtained authorization for every piece of material is a question deliberately obscured.
Anthropic's uniqueness lies only in its overreach—directly raiding entire pirated libraries, getting caught, and paying dearly.
From this perspective ( perspective : perspective, adjusted for clarity), Anthropic's accusations against Chinese firms expose a dangerous double standard among AI giants: 'I can train my model on global data, but you can’t train yours on my model's outputs.'
This reflects both commercial interests and geopolitical shadows.
Commercially, AI large model companies seek to build a closed-loop business model. They sell model 'intelligence' as a metered commodity via API services.
Allowing competitors to 'distill' this intelligence cheaply would undermine the entire model's foundation. Thus, they must define 'distillation' as illegal and deploy all public opinion ( public opinion : public opinion, kept as-is) and legal tools to combat it.
Geopolitically, Anthropic's accusations align perfectly with U.S. strategies to slow China's AI development. Elevating commercial competition to 'technology theft' creates public opinion for further technical blockades and export controls.
This imbues Anthropic's commercial actions with a strong 'political correctness' hue, simultaneously attacking rivals and appeasing domestic political climates.
However, accusations built on double standards will ultimately backfire. When an industry leader gains advantages by breaking rules and skirting legal edges, it forfeits legitimacy in setting industry norms.
For Anthropic, before lecturing others on 'responsibility,' it should first explain more candidly to the public that beneath its righteous 'thief-catcher' facade lies North America's biggest AI 'data thief.'
- END -
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







