The 1000x Efficiency Myth: How Taalas Outperforms NVIDIA with 'Model-as-Chip'
 02/28 2026
02/28 2026
 637
637
In February 2026, the calm of the AI computing power industry was shattered by a Canadian startup.
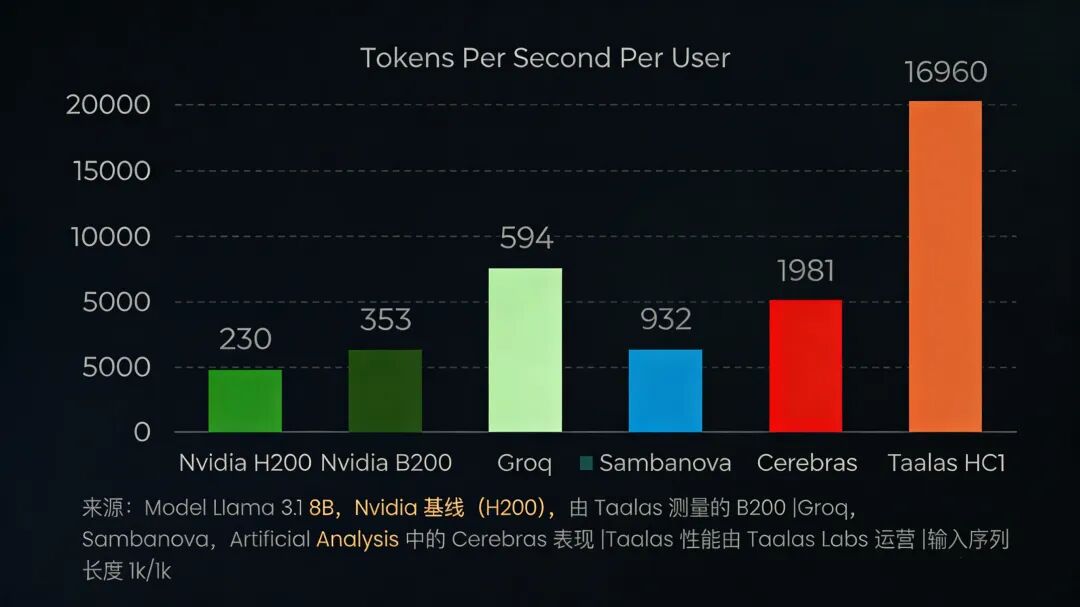
Founded by former AMD and NVIDIA architect Ljubisa Bajic, Taalas emerged with its 'Model Based' chip architecture and over $219 million in cumulative funding. The company boldly claims to 'boost AI model efficiency by 1000x,' asserting that its first product, HC1, can achieve an inference speed of 17,000 tokens per second, reducing the inference cost of the Llama 3.1 8B model to 0.75 cents per million tokens—just 1/266th of traditional GPU cloud services.
As NVIDIA 'absorbs' Groq through a $20 billion inference technology licensing deal and the entire industry becomes trapped in a race for general-purpose computing power, Taalas' 'hardcore model' approach not only redefines Moore's Law but also signals a shift in the AI computing power market from 'general-purpose dominance' to a 'coexistence of general-purpose and specialized' fragmented landscape. This article delves into Taalas' technological revolution, commercialization challenges, and the long-term impact of this architectural rivalry on the global AI industry.
A 'Non-General-Purpose' Gamble Is Quietly Underway
Taalas was born out of Bajic's deep dissatisfaction with the current state of AI computing power. After leading the development of Tenstorrent's scalable AI accelerators, this veteran chip designer co-founded Taalas in March 2023 with engineers Drago Ignjatovic and Lejla Bajic, with a core mission to 'commoditize artificial intelligence.'
'Artificial intelligence is like electricity—an indispensable necessity that must be available to everyone,' Bajic stated at the company's unveiling. 'Commoditizing AI requires a 1000x improvement in computing power and efficiency, which cannot be achieved through current incremental approaches.'
This 'non-incremental' mindset set Taalas on a collision course with NVIDIA from the start. The company completed two funding rounds between August 2023 and March 2024, with the first $50 million led by Pierre Lamond and Quiet Capital, raising its total valuation to $219 million. Notably, investor Pierre Lamond directly praised the team's experience: 'They have top-tier chip expertise, and this direction can achieve a 1000x cost improvement, driving AI to become an infrastructure-level capability.'
Taalas' research and development efficiency is equally remarkable. Its first product, HC1, was designed by a 24-person team with just $30 million in R&D costs and partnered with TSMC to achieve an 'extremely fast' production cycle of '2 months from model weights to deployable hardware.' Originally scheduled for customer delivery in Q1 2025, the latest news indicates that the chip has entered technical verification, with its extreme performance reshaping industry perceptions of inference computing power.
Model Based Architecture: 'Hardcoding' Large Models into Silicon
Taalas' 1000x efficiency myth does not stem from mystical breakthroughs but from a radical redesign of traditional AI chip architectures. Unlike general-purpose GPUs, which 'load models into memory and run them via software scheduling,' Taalas adopts a 'Model Based' architecture that directly hardcodes the training results of specific large models at the transistor level, achieving a physically 'hardcore model.'
Traditional GPUs reserve significant computational units and scheduling logic to accommodate multiple models and tasks, leading to high hardware redundancy. Taalas' architectural innovation is essentially an 'extreme trade-off between efficiency and flexibility':
1. Hardware-Fixed Weights
Using a mask ROM recall fabric + SRAM architecture, weights for models like Llama 3.1 8B are directly written into the hardware, completely bypassing the cost and power bottleneck of high-bandwidth memory (HBM). This 'hardwired' design eliminates reliance on external memory read/write operations, fundamentally reducing latency and energy consumption.
2. Single-Model Specialization
Each HC1 chip supports only one model, sacrificing flexibility for ultimate performance. In real-world tests, its inference speed reached 17,000 tokens per second—50 times faster than NVIDIA's H200 GPU (230 tokens per second) and far surpassing specialized accelerators like Cerebras WSE (2,000 tokens per second).
3. Cost and Power Optimization
Thanks to architectural simplification, HC1's hardware costs are 20 times lower than traditional solutions, with power consumption reduced by 10 times. For data centers, this means 'running equally scaled models at 10% power consumption,' completely rewriting AI return on investment curves.
Zhao Yongwei, an associate researcher at the Institute of Computing Technology, Chinese Academy of Sciences, highly evaluated this technical approach: 'While Taalas may not yet have practical applications, it could become a historically significant chip. This hardwired model represents a major trend in future chip development. Taalas bears the current skepticism, making it easier for successors to promote related concepts.'
Flaws Remain: The Accuracy Cost Behind '2000 Words per Second'
Behind extreme speed lies an unavoidable shortcoming in the first-generation product. In real-world tests, while HC1 achieves an astonishing '2000-word response per second,' the response quality is notably flawed—not only making simple calculation errors but also 'fabricating' answers in complex scenarios.
The core issue lies in HC1's use of fixed-point number formats in its first generation, which cannot meet the precision demands of complex inference. To mitigate this risk, Taalas has already planned the second-generation HC2, which will switch to a standard 4-bit floating-point format to improve accuracy while expanding model support to 20 billion parameters, aiming to cover GPT-5-level systems by the end of 2026.
'It feels like cheating—so fast,' Basecamp founder DHH remarked after testing HC1. Cambrian-AI chief analyst Karl Freund described its performance as 'insane.' This 'speed vs. accuracy' contradiction has become Taalas' core challenge for commercialization.
The Survival Logic of 'One Model, One Chip'
In Bajic's vision, Taalas does not aim to replace NVIDIA GPUs but to fill the market gap between 'general-purpose computing power and ultimate efficiency.' The company has explored three commercialization paths: building its own API, selling chips directly, and collaborating with model developers for custom chips, all centered on 'locking in high-stickiness vertical scenarios' to drive the 'one model, one chip' customization trend.
Core Deployment Scenarios: Edge Revolution from Intelligent Customer Service to Autonomous Driving
Taalas' product positioning precisely targets three application scenarios sensitive to latency and requiring stable model versions:
Enterprise-Specific Model Scenarios
Enterprises in finance, healthcare, and legal sectors often rely on fixed-version private models for extended periods. For these clients, HC1's cost advantage is overwhelming—reducing inference costs to 1/266th of traditional solutions, making many previously unfeasible AI applications commercially viable.
Edge Inference Scenarios
Humanoid robots, autonomous vehicles, and high-end smartphones demand extreme real-time performance without needing to run multiple models.
Large-Scale Customer Service Scenarios
E-commerce and telecom intelligent customer service systems continuously run standardized dialogue models, prioritizing response speed over complex reasoning. HC1's 'instant responses' significantly enhance user experience while cutting operational costs by over 90%.
Paresh Kharya, Taalas' VP of Product, stated: 'The optimal silicon for model customization won't replace large GPU-based data centers but will fit specific applications.' This 'complementary, not substitute (replacement)' positioning has carved out survival space for Taalas under NVIDIA's shadow.
Dual Tests: Model Iteration and Ecosystem Barriers
Despite clear scenario targeting, Taalas' business model faces two core uncertainties:
First is model iteration risk. The 'one model, one chip' approach requires clients to make long-term commitments to specific models. With rapid evolution in large model architectures, existing specialized hardware could quickly depreciate if the industry shifts to revolutionary designs (e.g., beyond Transformers). Taalas' strategy is to bet on the long-term dominance of open-source architectures like Llama while optimizing chip-fixed model adaptability through LoRA fine-tuning.
Second is ecosystem weakness. NVIDIA's true moat lies not in hardware but in its CUDA software ecosystem and developer dependency. In contrast, Taalas' specialized chips lack matching (supporting) development toolchains, forcing developers to re-adapt and raising migration costs for clients. Building its own ecosystem quickly has become critical for Taalas' scalable adoption.
Taalas' rise is not an isolated industry phenomenon. By late 2025, NVIDIA's $20 billion inference technology licensing deal with Groq signaled 'the general-purpose computing power giant's compromise to specialized inference.'
Founded by Jonathan Ross, a core developer of Google's TPU, Groq's LPU inference chips also use specialized architectures, achieving ultra-low latency through deterministic design and on-chip SRAM memory. NVIDIA rapidly filled its inference gaps through 'non-exclusive technology licensing + core talent acquisition' while mitigating acquisition risks. Reports suggest NVIDIA's next-gen Feynman GPU may integrate Groq's LPU units by 2028, forming a 'general-purpose + specialized' hybrid architecture.
This rivalry reflects AI's transition from 'model training' to 'scalable inference deployment.' As the interval between large model releases lengthens, enterprises increasingly rely on mature models, rapidly expanding the market for specialized inference chips.
The future AI computing power market will feature a 'tripartite' landscape: NVIDIA GPUs dominate training and general-purpose inference, 'model-as-chip' firms like Taalas capture high-stickiness vertical scenarios, while cloud vendor chips like Google TPU and Microsoft Azure Maia focus on cloud-native inference. This fragmentation will shatter NVIDIA's monopoly, ushering in an era of 'specialized division of labor' in AI computing power.
For Taalas, 2026 will be a pivotal year. The launch of its second-generation HC2 will validate its technological scalability, while commercialization success will determine capital confidence in the 'model-as-chip' approach. To realize Bajic's vision of 'commoditizing AI,' Taalas must overcome three hurdles:
First, balancing accuracy and speed. Whether HC2 can maintain HC1's extreme speed while significantly improving inference accuracy with 4-bit floating-point formats will determine its entry into high-precision fields like finance and healthcare.
Second, achieving cost and scale breakthroughs. HC1 remains in technical verification without public pricing. To fulfill its '1/266 cost reduction' promise, Taalas must lower manufacturing costs through mass production while optimizing supply chain management.
Third, accumulating ecosystem partners. Establishing deep collaborations with model firms, cloud providers, and vertical industry clients to build a 'model customization-chip design-scenario deployment' closed loop (closed loop) is essential to shed its 'niche technology' label and become an industry standard setter.
From a longer-term perspective, Taalas' exploration concerns not just a startup's survival but the future trajectory of the AI industry. If the 'model-as-chip' approach proves viable, it will shift AI computing power from 'pursuing generality' to 'pursuing ultimate efficiency,' enabling AI to permeate all industries and realizing Bajic's vision of 'making AI as ubiquitous as electricity.'
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







