What are the Technical Features of XPENG and LIXIANG's Bets on VLA?
 03/19 2026
03/19 2026
 545
545
As advanced driver-assistance systems become more sophisticated, the use of highway NOA and urban NOA has become widespread, largely driven by the advancements in VLA (Vision-Language-Action) models.
The emergence of large VLA models marks the industry's formal transition from 'perception and recognition' to 'comprehension and decision-making.' Previous intelligent driving systems were more like experienced 'reflex nerves,' stopping at red lights and avoiding obstacles without understanding the reasons behind these actions.
VLA models directly link human common sense, logical reasoning, and driving behavior. By combining vast amounts of image data with language comprehension, the model no longer merely calculates pixels but 'observes' and 'understands' the causal relationships in the physical world like a human, ultimately outputting control commands such as steering wheel angles and brake force. This leap from input to output enables vehicles to handle unseen new scenarios.
Simply put, VLA models enable vehicles to 'understand the world, interpret intentions, and take actions.'
Image Source: Internet
Recently, LIXIANG and XPENG have successively released their latest VLA models, propelling the technological competition in autonomous driving into a new phase. What are the unique features of these VLA models released by the two companies? What problems in autonomous driving do they address? Today, 'Frontiers of Intelligent Driving' will explore these questions.
Before diving into today's topic, let's clarify that the content is sourced from announcements made by LIXIANG and XPENG. If there are any ambiguities or errors, we welcome corrections in the comments section.
LIXIANG MindVLA-o1: Simulating the Future in Latent Space
From the introduction of LIXIANG's MindVLA-o1, it is clear that the model emphasizes 'systematic design.' It is not just a single model but a complete closed-loop system encompassing data, model training, and deployment.
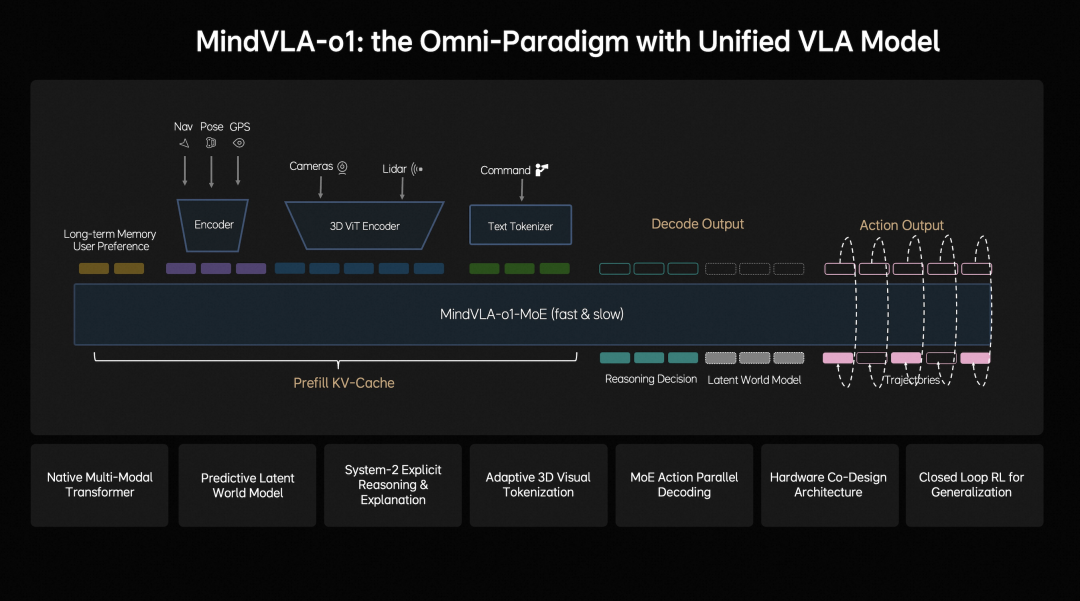
Image Source: LIXIANG WeChat Official Account
LIXIANG explicitly incorporates 3D modeling capabilities. By combining visual models with LiDAR point clouds as geometric cues, the model forms a more stable spatial representation internally. Compared to pure vision-based approaches, this method emphasizes 'physical consistency' and is better suited for handling complex spatial relationships such as occlusions, ramps, and irregular obstacles.
LIXIANG also introduces a predictive latent world model in MindVLA-o1, enabling efficient simulation of future scenarios in latent space. Simply put, the model can not only perceive the present but also simulate scene changes seconds into the future internally. For autonomous driving, many driving actions are essentially predictions of the future, and this capability, if well-executed, can significantly enhance decision-making stability.
In behavior generation, LIXIANG adopts more structured approaches such as VLA-MoE (Mixture of Experts) + Action Expert, parallel decoding, and discrete diffusion. The goal of these designs is to ensure that the output trajectories are more temporally continuous and physically plausible.
LIXIANG also invests heavily in simulation and reinforcement learning, conducting large-scale training in controlled environments and combining it with real-world data-driven closed loops. This approach allows for coverage of numerous long-tail scenarios without relying solely on real-world data collection.
Additionally, LIXIANG considers hardware constraints during the model design phase, optimizing deployment efficiency through hardware-software co-design. This is a crucial step for the practical implementation of large models.
Overall, LIXIANG's MindVLA-o1 represents a long-term capability-building approach, emphasizing the integrity of the model structure, training system, and engineering closed loop.
XPENG's Second-Generation VLA: More Product-Oriented and Data-Driven
XPENG's second-generation VLA places greater emphasis on rapid deployment in real-world user scenarios. Its core philosophy is to minimize reliance on rules, using large models to directly learn driving behaviors and continuously iterate through vehicle-end data.

Image Source: XPENG WeChat Official Account
A key feature is the use of continuous video streams. Unlike traditional methods that rely solely on keyframes or abstract features, XPENG emphasizes temporally continuous information input, making the model more stable in handling dynamic scenarios such as decelerating leading vehicles or crossing pedestrians, with no abrupt changes in decision-making.
In perception, XPENG does not emphasize complex explicit 3D reconstruction but relies more on the model itself to learn spatial relationships. This approach simplifies the structure and increases end-to-end integration but places greater demands on data scale and model capabilities.
Another notable feature of XPENG's second-generation VLA is its 'tiered product strategy' (comprising three versions). The high-computing-power platform supports full capabilities, which are then distilled and compressed for mid-to-low-computing-power vehicle models. This is a typical engineering compromise that ensures both technological superiority and rapid scalability.
From an experience perspective, XPENG focuses more on user-perceptible metrics such as the number of takeovers and harsh braking. This indicates that its optimization goals prioritize 'natural driving and peace of mind' over purely technical metrics.
Furthermore, XPENG emphasizes 'hardware-software integration.' Through its self-developed Turing AI chip, they maximize the effective computing power of the hardware. In XPENG's architecture, the model is no longer an isolated algorithm but a deeply integrated system with the chip's instruction set and AI compiler. This design enables the model to process video stream data at extremely high frequencies, ensuring real-time responsiveness in complex driving conditions.
Overall, this is a data-driven approach focused on rapid iteration and scalable deployment. XPENG's technical logic is clear: given the vast and continuous data in the physical world, the goal is to digest this massive (massive) information through the most powerful computing base and efficient model architecture.
Frontiers of Intelligent Driving's Perspective?
Comparing the two approaches, 'Frontiers of Intelligent Driving' believes they address the upper limits of autonomous driving by focusing on different areas. LIXIANG attempts to teach vehicles to think like humans about physical laws by constructing a perfect physical model and simulator, enabling them to find answers in unknown environments. Its strength lies in scene fidelity and future prediction accuracy, making its vehicles more composed and logical in complex intersections and human-vehicle interactions.
In contrast, XPENG prioritizes system explosiveness and execution efficiency. It emphasizes that the capabilities brought by large models must be built on efficient computing power utilization, so they focus on ensuring smooth operation and high throughput of large models on limited edge devices.
If LIXIANG is enhancing the vehicle's 'IQ,' XPENG is unleashing the brain's potential by reconstructing the body's structure (chip and compiler).
From the technologies released by these two companies, a clear trend emerges: autonomous driving is accelerating toward embodied intelligence. Whether it's LIXIANG's 'digital brain' analogy or XPENG's reconstruction of the 'physical AI' foundation, both convey the same idea—that the vehicle is merely the first carrier for AI to interact with the physical world.
The future core competitiveness will no longer be about how well a single function performs but about who can build the most versatile and fastest self-evolving underlying architecture.
In my view, the current challenge lies in the efficiency threshold for edge deployment. No matter how intelligent the model is, if the latency is too high when running on the vehicle, it's all for naught. Therefore, XPENG's approach of reconstructing from the bottom layer (bottom-layer) chip level holds strong long-term technical moats. Meanwhile, LIXIANG's closed-loop reinforcement learning through world models strikes a balance between data acquisition costs and model evolution efficiency.
In the future, these two paths may converge, achieving large-scale self-evolution through world models on a powerful hardware foundation.
-- END --
-
![]()
WeChat Collaborates with Huawei/Honor/Xiaomi on A2A: Is This the Dawn of AI Integration?
-
![]()
NVIDIA RTX Spark: Powerful, Yet Not the Ideal Choice for the Agent Era
-
![]()
NVIDIA RTX Spark: Powerful, but Is It the Right Fit for the Age of Agents?
-
![]()
A Genuine Threat or Just a Publicity Stunt? World's Premier AI Firm Warns: AI Evolving Autonomously, Slipping Beyond Human Control
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital





