The Copyright Quagmire and the Fall of Sora
 04/13 2026
04/13 2026
 638
638

On March 24, OpenAI made the announcement to shut down Sora, the AI video generation platform that once dazzled us with its declaration that "reality no longer exists," bowed out after a mere six-month run.
Some attribute this to a strategic shift in business, while others point to the prohibitive computational costs. Yet, there's a pivotal factor—copyright—that is often overlooked.

Sora utilized a black-box training approach, likely tapping into a vast reservoir of unauthorized online video data. Since its inception, copyright holders such as Disney have vehemently opposed Sora, even taking legal action against OpenAI. The president of Nintendo also voiced concerns over intellectual property issues with generative AI at a shareholders' meeting.
Every decision is a calculated move, and OpenAI's choice to discontinue Sora serves as a stark warning to all AI video generation tools currently available: in the current legal and industrial climate, neglecting copyright issues is a recipe for failure.

Sora's copyright dispute is a glaring example. In truth, Sora's black-box training is not an anomaly but a prevalent practice in the industry. Other video generation models also grapple with copyright issues to varying extents, either due to limited open access, focusing solely on a niche market (e.g., serving only B2B commercial clients with minimal exposure), or deliberately steering clear of high-risk IPs like Disney characters to avoid legal repercussions from what some dub "the world's most formidable legal department."
Once in the crosshairs of copyright holders, all face the same litigation risks as OpenAI. For instance, a domestic AI video tool found itself embroiled in a lawsuit in California, sued by Hollywood titans Disney, Warner, and Universal for generating unauthorized characters from works like "Star Wars" and "Minions."
AI behemoths generally adopt a "act first, negotiate later" stance on copyright issues.
They train on publicly available datasets, often scraped without permission, containing a wealth of copyrighted content. Only after product launch, when confronted with complaints from entities like The New York Times or individual creators, do they seek partnerships or make payments to legitimize their data sources.
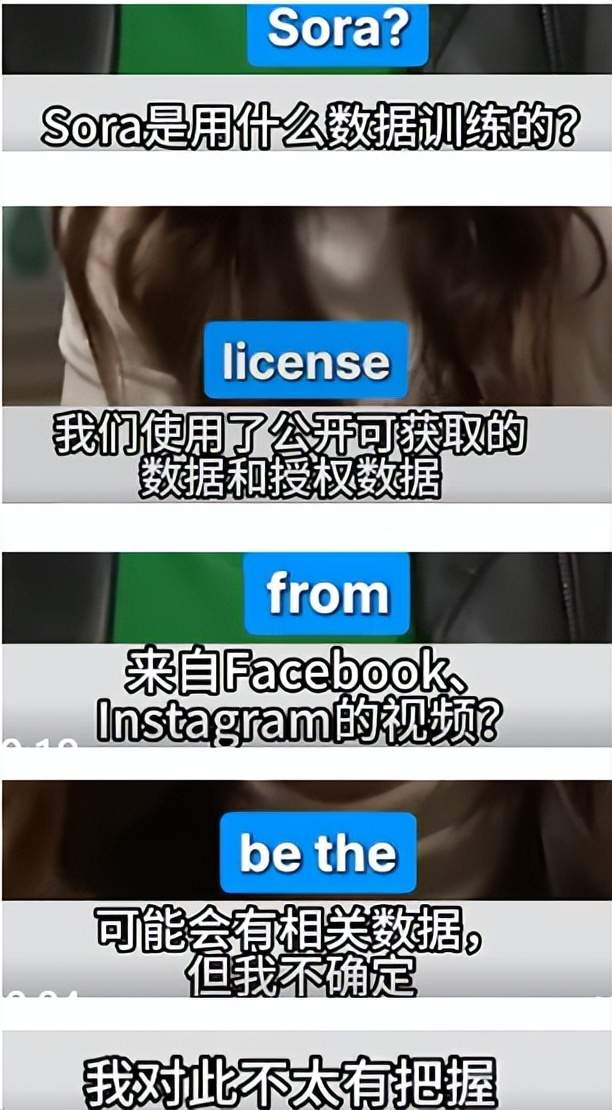
Mira Murati, OpenAI's former CTO, publicly acknowledged uncertainty about whether Sora utilized copyrighted videos for training.
In contrast, content platforms with stringent anti-scraping measures and paywalls, such as scientific journals and paid databases, are better equipped to mitigate AI infringement risks. Even if AI can scour the internet for published papers, it can only access public pages without bypassing login or payment verification.
Stringent copyright protection has rendered scientific content a rare, infringement-free zone, causing many general-purpose AIs to rely on incomplete information when addressing scientific queries. However, these copyright protection methods are challenging for entertainment institutions and creators in the film/animation industry to implement.
One reason is the ineffectiveness of paywalls. Scientific papers can precisely control access, allowing only subscribers to view full texts, with AI operating within closed systems. Videos, on the other hand, are mass cultural consumer goods, with YouTubers primarily monetizing through ads and communities. Most video content is publicly accessible, making it easy prey for AI.

Secondly, determining rights in gray areas is complex. Scientific content adheres to clear data and regulations, making infringement easily identifiable. However, AI's ability to learn, abstract, reorganize, and generalize visual styles, character images, and narrative logic from videos complicates matters. AI-generated works can dismiss claims with excuses like "coincidental ideas" or "similar tropes," making it difficult for creators to provide evidence.
Thus, the "act first, negotiate later" approach, seeking forgiveness rather than permission, has become commonplace among AI giants in video generation. Since copyright mechanisms fail to adequately protect creators, is their existence still justified?

On one hand, public entertainment content is extensively scraped for AI training, with individual creators virtually powerless to halt it. On the other hand, strictly restricted scientific content hampers AI progress in research.
Consequently, some tech pioneers, futurists, and radicals argue that copyright systems, relics of the industrial age, have become monopolistic tools for big capital. They not only fail to benefit ordinary creators but also hinder technological inclusivity, advocating for complete abolition and full openness.

Others contend that AI tools like Sora fulfill ordinary people's directorial aspirations, bringing tangible benefits and fostering innovation by enabling more users to create. They argue for protecting such tools for the majority's welfare.
But is the issue truly so black and white?
This represents a classic "trolley dilemma," forcing a binary choice between big corporations and a few creators, or majority users and a few creators, while overlooking a crucial fact: today's uncompensated video creators could be you or me tomorrow.
AI initially learned from fringe creators like illustrators, writers, photographers, and music producers. The literary and artistic circles protested AI infringement, which later expanded to white-collar workers, artists, coders, and broader groups. Some high-level workers' skills are uncompensatedly learned by AI and distilled into "skills." Isn't this also a form of "style learning"?

Creators can be any ordinary person relying on unique skills for a living. Perhaps only when AI threatens their livelihoods do people understand the anger of video creators like directors, content creators, and YouTubers.
The core role of copyright systems is not to pit humans against each other—protecting big corporations or small individuals—nor solely about distributing profits. Their value lies in recognizing the legitimacy of creators' rights.
In 1710, the Statute of Anne first established authors as copyright owners, overturning the previous printer-centric monopoly system. For three centuries, this system has inspired countless individual creations. Today, we may need to reform copyright to suit AI's needs, but we must not obscure its recognition of individual rights with "copyright capitalization."
It resembles labor protection laws. Although the eight-hour workday is hard to enforce strictly, its existence establishes the legitimacy of workers' rights.

Facing AI video generation tools' uncompensated use of original content, creators are fighting back. Generally, institutional forces and industry giants' counterattacks have been more effective, while individual, verbal resistance remains weak.
The primary constraints on tools like Sora come from legislative pressure and content giants' dual exertion.
The U.S. Copyright Office's precedents require AI-generated content to bear AI identification and automatically add copyright logos when using corresponding styles.
Copyright giants have also taken serious measures against AI's "style learning." Hollywood's top three agencies and film giants like Disney, Warner, and Universal have issued legal warnings to OpenAI, demanding an end to the default use of artists' images and works for training Sora. This forced OpenAI to introduce an "opt-out" mechanism for Sora 2, allowing copyright holders to request removal of their works from training sets.
Some creators use technical tools to embed invisible perturbing pixels or watermarks in videos/images to disrupt AI's style learning, which can be effective.
Entirely ineffective counterattacks include failed negotiations, such as the industry's proposed authorized payment + revenue-sharing system, which collapsed with Sora's shutdown. Another is verbal "magic attacks," like directors and photographers publicly declaring "not using Sora" and urging peers to boycott it. However, this fails to stop users from creating AI video memes, lacking real-world binding force.
Only organizational forces like legislators and giants can counterbalance tech capital, a harsh reality for human creativity in the AI era. What can be done?

The copyright tug-of-war between humans and AI giants ended with Sora's voluntary shutdown, but this is not a human victory. It merely reflects AI giants' decision to stop struggling in the quagmire of ongoing copyright lawsuits, creator boycotts, and ethical controversies.
Sora's demise serves as a cautionary tale, reminding us that AI lacks clear red lines.
Political scientist Francis Fukuyama argued: Facing technological progress, we must artificially, even arbitrarily, draw red lines. Even if 81 km/h is not inherently more dangerous than 79 km/h, an 80 km/h limit must be set.
In AI, this red line means respecting human labor and creative sovereignty as a prerequisite for development. Without this uncrossable line, ambiguity breeds disorder and backlash, failing to gain social acceptance. Establishing clear prohibitive principles against AI's uncompensated use and "style learning" of human works protects not only human creators but also AI developers and enterprises. Creator resistance accelerated Sora's shutdown, representing a loss for OpenAI and its users.

Fukuyama emphasized that legislators must act to establish rules and mechanisms amid rapid technological change. If legislators shirk these responsibilities, other social institutions and actors will step in.
This time, human creators decided to resist AI and Sora. Sora's shutdown temporarily avoids conflicts over missing red lines. However, numerous AI video generation tools remain, repeatedly testing the invisible red line in people's minds until it becomes clear and explicitly enshrined in copyright law.
Only then can human creators and AIGC technology truly reconcile. Hopefully, this red line will not arrive too late.

-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






