Will Choosing the Wrong Technical Route Between World Model and VLA Lead to Elimination?
 06/29 2026
06/29 2026
 488
488
As we pass the midpoint of 2026, the technical routes in the autonomous driving industry are becoming increasingly contentious. From the comprehensive adoption of end-to-end large models in vehicles in 2025 to the open intensification of the two routes—VLA (Vision-Language-Action Model) and World Model—in 2026, the choice of technical route has become a critical decision for every automaker. At NVIDIA's GTC conference, Li Chuanhai, CTO of Geely Automobile Group, and Cao Xudong, CEO of Momenta, publicly questioned VLA. Jin Yuzhi, CEO of Huawei's Automotive BU, directly called VLA a clever but flawed solution, advocating for the replacement with a World Behavior Model. On the other side, companies like Li Auto, XPENG, and Yuanrong Qixing are firmly advancing the mass production and implementation of VLA architectures. What are the key differences between these two routes? Does choosing the wrong direction mean falling behind?
What Are VLA and World Model Competing For?
To clarify what VLA and World Model are competing for, we must first understand the problems each solves.
VLA, or Vision-Language-Action Model, introduces a crucial intermediate layer—language—between visual perception and action execution. This language is not about making the car speak but using the reasoning capabilities of large language models to make driving decisions. Simply put, VLA processes road conditions, uses a language model to understand the scene's implications, and then decides how to act. Liu Xianming, head of XPENG's General Intelligence Center, succinctly summarizes that VLA learns how humans would act in the world.
The logic of the World Model is entirely different. It is not concerned with how humans act but with how the world itself changes. The core capability of the World Model is prediction—not predicting what the next image will look like but how the physical world will evolve after the vehicle takes a specific action. For example, if the system sees a bouncing ball on the roadside, the World Model, based on its understanding of physical causality, would predict that a child is likely to run out from behind the ball. Waymo's World Model, first unveiled at CVPR 2026, is built on Google DeepMind's Genie 3 architecture and can predict the dynamic evolution of road scenes, including the behavioral intentions of other vehicles and pedestrians.

Image Source: Internet
From a technical perspective, VLA centers on linguistic intelligence, attempting to describe and reason about the three-dimensional physical world using one-dimensional text tokens. In contrast, the World Model centers on spatial intelligence, directly modeling physical laws and causal relationships in a continuous state space. The two approaches fundamentally differ in how they process the world: one describes, while the other simulates.
The differences in technical routes do not necessarily mean mutual exclusivity. Ideal's MindVLA-o1 introduces a predictive latent space model within the VLA framework, enabling the simulation of future scene changes in latent space. XPENG's second-generation VLA is also officially defined as both an action generation model and a physical world understanding and reasoning model. Liu Xianming has explicitly stated that the World Model and the second-generation VLA are not mutually exclusive or competitive but rather enhance the model's understanding and action capabilities in the physical world through different training signals. In fact, a consensus is emerging in the intelligent driving industry that VLA is responsible for perceiving the current environment, understanding semantics, and deciding the next action, while the World Model is responsible for predicting how the scene will evolve over the next 5 to 10 seconds.
How Are Mainstream Players Aligning?
Although there is a trend toward the integration of VLA and World Model, significant differences remain in each company's R&D investment and resource allocation.
Huawei, a staunch advocate of the World Model route, first proposed the World Model technical route in 2025 with the release of the WEWA 1.0 architecture in ADS 4. Huawei's technical solution involves deploying a world engine in the cloud, generating difficult scenarios through AI, and increasing the density of long-tail scenarios by 1000 times. On the vehicle side, a World Behavior Model is deployed, making decisions based on multi-sensor full-modality perception. Huawei expects over 80 models equipped with Qiankun Intelligent Driving by 2026, with a total of 3 million vehicles by the end of the year, and R&D investment is expected to exceed 18 billion yuan in 2026.

Image Source: Internet
Waymo has also chosen the World Model direction. In early 2026, Waymo released the Waymo World Model based on Google DeepMind's Genie 3 architecture. This model can generate virtual driving environments based on text prompts for training the system to handle various edge scenarios. At CVPR 2026, Waymo further disclosed its complete training framework for the World Model, which is divided into three stages and draws on the training paradigm of large language models.
In the pre-training stage, Google DeepMind's Genie 3 general World Model is directly reused. This model has already learned physical laws and scene evolution capabilities from massive video data. In the mid-training stage, Waymo's accumulated over 200 million miles of autonomous driving data are injected into the model, enabling Genie 3 to understand inputs from autonomous driving -specific sensors such as multi-camera, LiDAR, and millimeter-wave radar, transforming general visual cognition into spatial perception tailored to driving scenarios. In the post-training stage, fine-tuning and distillation are performed for specific tasks such as long-term simulation and planning, enabling the model to generate multi-sensor simulation data, including images and point clouds, and support the generation of long-tail scenarios such as tornadoes and road flooding, thereby serving large-scale simulation testing and edge scenario coverage.
The VLA camp is represented by companies such as Li Auto, XPENG, and Yuanrong Qixing. Li Auto's MindVLA-o1 is centered around a native multimodal MoE Transformer. At the perception layer, a 3D ViT encoder is used to restore video streams into three-dimensional space, integrating visual semantics with the geometric information from LiDAR point clouds. At the decision-making layer, an implicit World Model is introduced based on the language model, allowing for the preview of scene changes in latent space over the next few seconds. The Action Expert module then parallelly decodes to generate trajectories compliant with vehicle dynamics. The complete training process of Li Auto's MindVLA-o1 model is divided into three stages: first, pre-training the World Model representation with videos; then, continuously evolving it within MindVLA; and finally, jointly aligning the World Model, reasoning, and behavior generation.
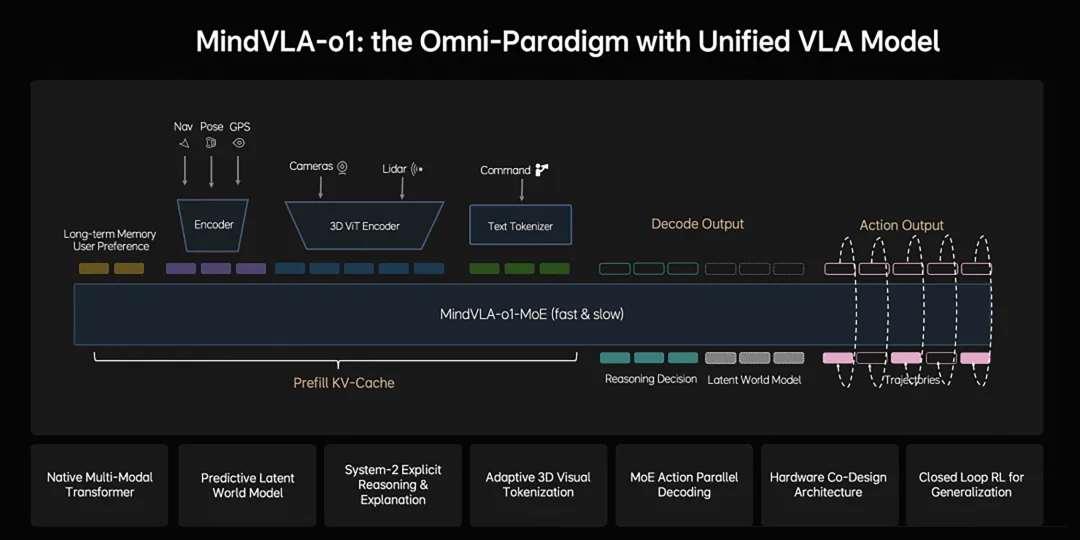
Image Source: Internet
XPENG's second-generation VLA removes the intermediate language translation step in traditional architectures, directly mapping visual inputs to vehicle control commands and reducing decision-making delay from 200 milliseconds to under 80 milliseconds. It relies on 72 billion cloud parameters and nearly 100 million scenario data points for training and is equipped with Turing chips as standard hardware to support real-time reasoning. XPENG defines the second-generation VLA as a model with both action generation and physical world reasoning capabilities, learning how to act reasonably from massive human driving behaviors.
Tesla's FSD V14 takes a slightly different approach. Building on the V13 end-to-end model, V14 further expands the model size, increasing the number of parameters by 10 times compared to V13, with a complete model size of about 12.5GB. Navigation, path decision-making, and obstacle avoidance logic are all incorporated into the neural network under a unified training framework.
Tesla also integrates the capabilities of xAI's Grok large model into the vehicle's decision-making system. Here, Grok is not used to turn the cabin into a chat tool but as an interpretive layer for the FSD decision-making system, enhancing the system's ability to understand intentions and provide explainable decisions. Vague instructions, multi-objective descriptions, and scenario constraints can all be translated by Grok into executable itinerary plans.
From an architectural perspective, this is equivalent to overlaying the reasoning capabilities of a language model on top of an end-to-end perception-control integrated framework, making the vehicle's performance in complex intersections, roundabouts, and highway mergers more like understanding the environment and making choices rather than a functional splice .
Momenta follows a World Model + Reinforcement Learning route. In April 2026, during the Beijing Auto Show, Momenta officially released the R7 Reinforcement Learning World Model and achieved its first mass production. Momenta CEO Cao Xudong positions the company as a builder of physical AI foundation models and explicitly states that the World Model and reinforcement learning together constitute the two core pillars of physical AI.
The R7 World Model can be divided into three layers. The first layer is World Model pre-training, where Momenta refines approximately 100 million golden data segments from over 12 billion kilometers of real driving mileage, compressing physical laws, common sense, and causal relationships into the model. The second layer is World Model simulation, where the World Model is used for closed-loop simulation of autonomous driving, allowing the system to predict how the world will evolve in response to its actions and efficiently evaluate long-tail scenarios. The third layer involves reinforcement learning within the World Model, where a high-fidelity virtual training ground is constructed based on the first two layers, allowing the system to repeatedly explore and make mistakes in an environment close to reality.

Image Source: Internet
This three-layer architecture closes the technical loop of pre-training, simulation, and reinforcement learning, enabling the R7 to empower the autonomous driving system not only to understand and comprehend the world but also to predict it, understanding the physical properties of objects, their motion causality, and potential interactions, thereby achieving more accurate prediction and planning.
From an industry-wide perspective, by April 2026, the penetration rate of new passenger vehicles in China equipped with L2+ or higher-level assisted driving functions as standard will exceed 41%. If optional configurations are included in the statistics, the penetration rate of L2 and L2+ reached 88% in 2025. High-level intelligent driving is moving from a niche luxury to a standard feature for the majority. In this process of rapid adoption, the choice of technical route may directly impact subsequent iteration speed and cost structure.
What Is the Debate About the Routes Really About?
The current online debate between VLA and World Model, on the surface, appears to be about technical solutions but is actually a discussion of two fundamental questions in the development of the autonomous driving industry.
The first question is where the intelligence of the autonomous driving system should come from. VLA's answer is that it should come from human knowledge and reasoning—using the common sense and logic learned by large language models from text data to make decisions in driving scenarios. The World Model's answer is that it should come from the laws of the physical world—learning how objects move and scenes evolve from massive video data to acquire predictive capabilities based on causality. Li Feifei's viewpoint in her November 2025 article is highly representative: spatial intelligence is the next frontier of AI, and linguistic intelligence cannot encompass all aspects of artificial intelligence.
The second question is in which space the model's understanding should occur. VLA compresses information from the three-dimensional world into one-dimensional language tokens and completes reasoning within a large language model. This compression inevitably leads to information loss, as text cannot fully represent critical elements such as distance, direction, and size in three-dimensional space. In contrast, the World Model directly models in a continuous state space, avoiding information loss caused by dimensional compression.

Image Source: Internet
However, VLA also has advantages that the World Model does not fully possess. The World Model can understand the causal relationship that not braking will lead to a collision and make the decision to brake accordingly. However, it lacks the semantic reasoning capabilities based on traffic regulations and social common sense that VLA possesses. For example, in scenarios where a police officer's hand signals take precedence over traffic lights, understanding involves not only avoiding physical collisions but also the priority rules in traffic laws and human society's go through conventions. The common sense and logic learned by VLA through language models can precisely handle such problems. Additionally, VLA can explain its actions to the driver in natural language, while the World Model can only output prediction results and action commands without providing human-readable decision reasons.
Both routes face significant challenges in terms of computational requirements. VLA models, which include large language models, have high computational and memory costs. Currently, the reasoning delay of VLA models is generally between 100 and 300 milliseconds, while the end-to-end delay for autonomous driving needs to be controlled within 50 milliseconds. High-fidelity reasoning in the World Model is even slower. Both need to find a balance between cloud training and on-vehicle deployment.
From the industry dynamics in 2026, a pure binary choice is being replaced by integration. XPENG simultaneously uses VLA and World Model to train its intelligent driving technology; Li Auto incorporates the World Model's predictive mechanisms within the VLA framework; Xiaomi's Xiaomi OneVL model, open-sourced in May 2026, unifies VLA, World Model, and latent space reasoning into a single framework. Industry analysts point out that VLA is suitable for complex semantic scenarios and human-machine interaction, while the World Model is suitable for large-scale training and long-tail scenario generation. The two routes are highly complementary and are expected to deeply integrate in the future.

Will Choosing the Wrong Path Lead to Elimination?
Back to the original question: Will choosing the wrong technical path lead to elimination?
In the short term, no. By 2026, neither VLA nor world models will have established an overwhelming technological advantage, nor will any company fall behind due to choosing the wrong path. Both approaches have their applicable scenarios and technical bottlenecks that need to be overcome.
However, in the long run, the risk of choosing the wrong path does not lie in choosing VLA over world models or vice versa, but rather in whether a company possesses the capability for continuous iteration and integration. An industry consensus has already formed: the era of modular small models has ended. The next phase of autonomous driving will be based on foundational models for the physical world. Whether it is VLA or world models, both will ultimately converge toward a unified foundational model architecture.
-- END --
-
![]()
Depreciation Rate on Par with Mobile Phones: Just 40% Value Retention After Three Years—Why Do Battery Electric Vehicles Lose Their Worth?
-
![]()
Clearing Bugatti Stock Worth 7 Billion: Why is Porsche 'Cutting Ties'?
-
![]()
Don’t Dismiss Huawei’s Potential in Sedans Just Because the Shangjie Hasn’t Hit It Big Yet
-
![]()
Unsold Cars in China Find Success Overseas
-
![]()
Ghosn: Only I Can Save Nissan, Shareholders Beg Me to Return
-
![]()
Expanding Automobile Consumption: It's Time to Address the High Cost of Electric Vehicle Repairs
-
![]()
Luna Ultra Entangled in 'National Subsidy Fraud' Controversy, Insta360 Pushed to the Brink by DJI
-
![]()
People have long suffered from splash ads. Will the 'temporarily disappeared' traffic behemoth make a comeback?







