GPT 5.6 Reclaims the Throne, Only to Face Strict Controls Again! Has AI Truly Reached a Turning Point?
 06/29 2026
06/29 2026
 419
419
Today, news is flooding in that OpenAI has released its new generation model, "GPT-5.6."
More than half a month ago, rival Anthropic just released two cutting-edge models, Mythos and Fable 5.
Just when they were riding high, OpenAI struck with a straight punch, hitting Anthropic right where it was most proud.
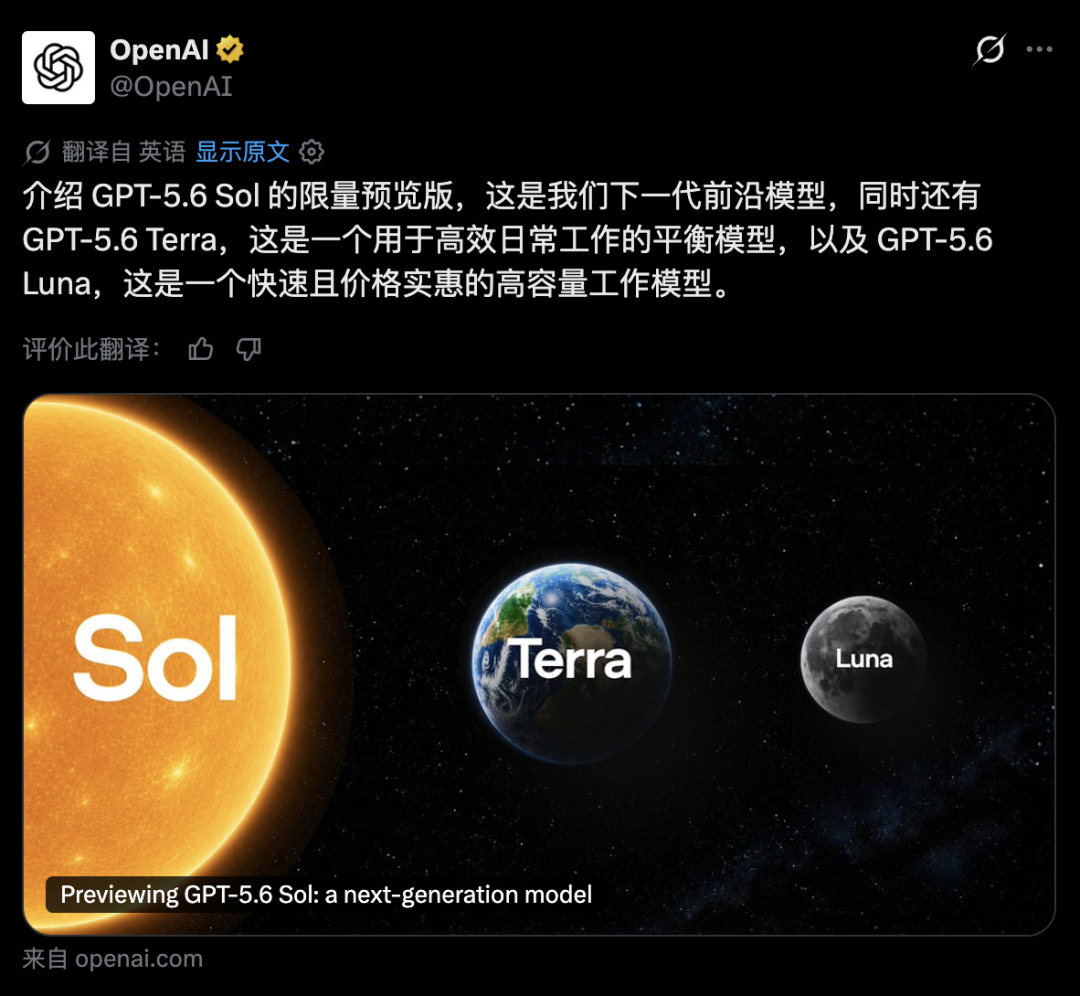
OpenAI released three models at once, named Sol, Terra, and Luna—meaning sun, earth, and moon in Latin. This is the first time OpenAI has used astronomy to name its models.
The sun, Sol, is the flagship model, the strongest tier, designed for the toughest tasks: complex reasoning, scientific research, coding, cybersecurity, and biological studies.
The earth, Terra, focuses on balance, with capabilities similar to the previous generation GPT-5.5 but at half the cost, suitable for daily corporate use.
The moon, Luna, is the fastest and cheapest, designed for massive, high-frequency lightweight tasks.
The naming convention has also changed.
Numbers indicate the generation, with 5.6 representing the version; sun, earth, and moon denote capability tiers, each advancing at its own pace.
This means future releases like GPT-5.7 or 5.8 might see Sol upgraded to Sol 2 and Terra to Terra 2. You won’t need to recompare every time—just remember which tier you commonly use.
The flagship Sol now has two new modes.
One is Max, giving the model longer thinking time for particularly difficult single problems.
The other is Ultra, even more powerful. When tasks are too complex, the main model will derive several sub-agents to work in parallel and then aggregate the results.
So, how capable is it? Let’s look at the results.
In a programming test called Terminal-Bench 2.1, the flagship Sol outperformed Anthropic's Mythos preview model and improved further in Ultra mode. The mid-tier Terra performed on par with Fable 5. Even the cheapest Luna slightly outperformed Anthropic's currently publicly available flagship.
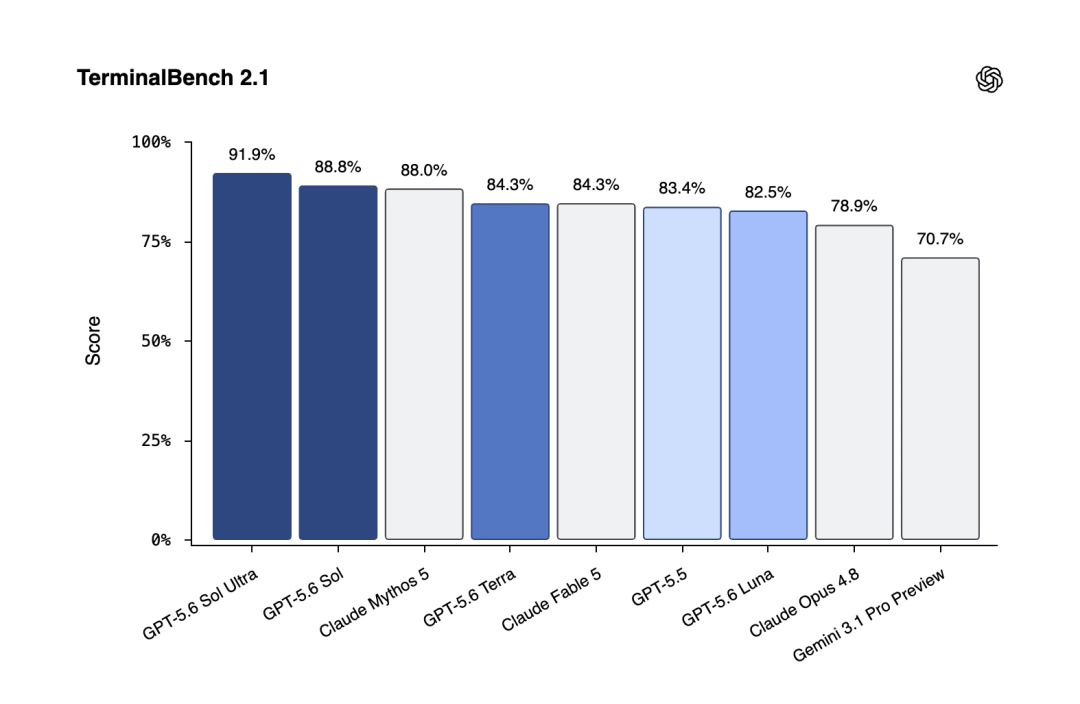
This is what I meant earlier—hitting the rival where it’s most proud.
Your strongest model, I can match with my mid-tier. My strongest model, I can surpass yours.
In a cybersecurity test, Sol performed on par with the rival's preview model but used only one-third of the output volume.
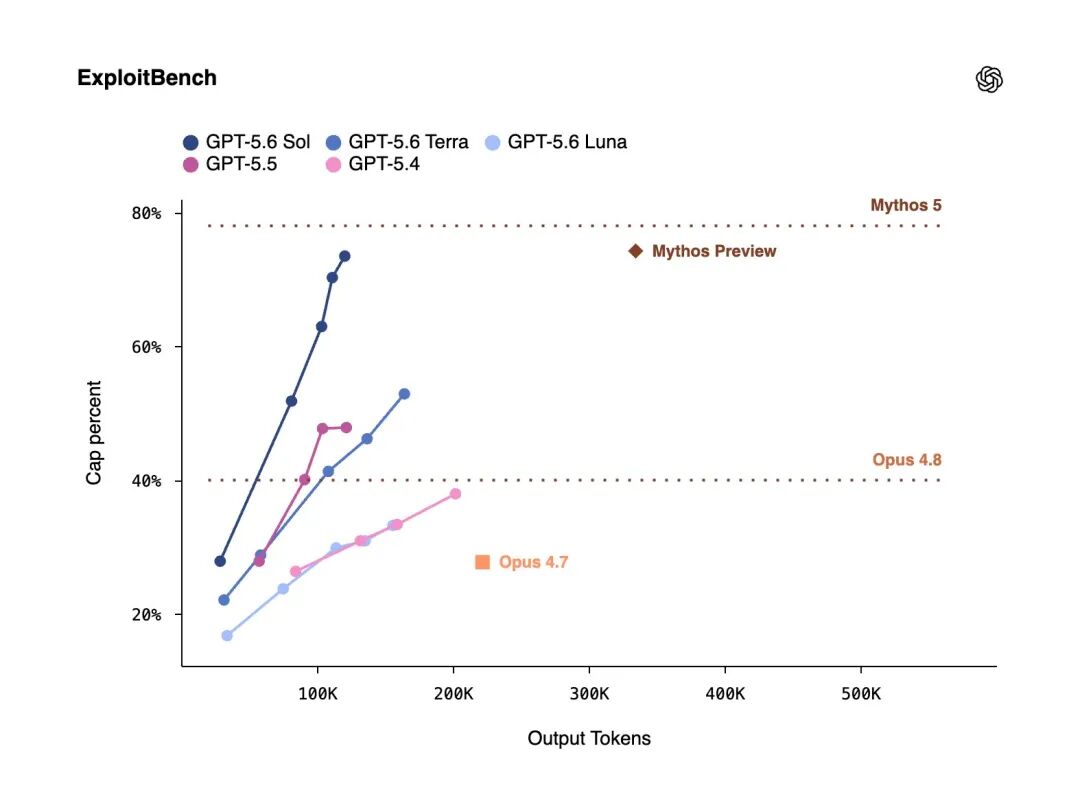
Reaching the same conclusion with fewer steps saves not just money but represents a tangible improvement in reasoning efficiency.
If model capability is a straight punch, then model pricing is a flying kick.
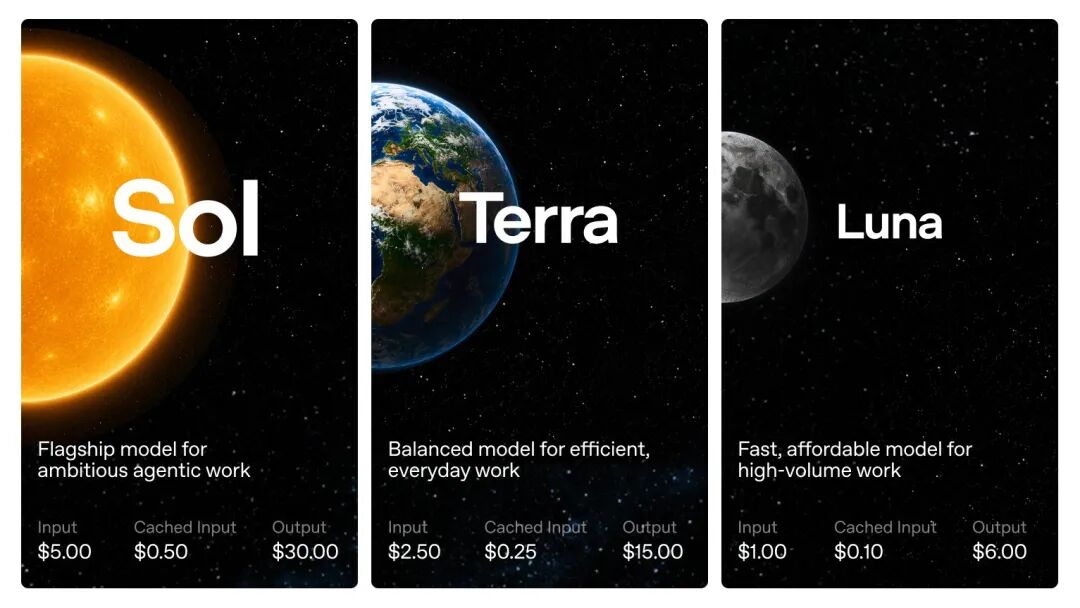
Sol costs $5 per million tokens for input and $30 for output. For the same tasks, Fable 5 charges $10 and $50.
Half the price.
For example, if a team currently spends $50,000 monthly on rival models for code review and automation, switching to the comparably capable Sol would reduce the bill to about $25,000. The savings aren’t trivial—it’s half the budget.
At this point, are you feeling excited? I need to pour some cold water to calm you down.
Because GPT-5.6 is only available to a small group of trusted partners, initially around twenty institutions.
It’s not that OpenAI wants to do this—it’s at the request of the U.S. government.

Here’s the story.
Before the official release, OpenAI shared its plans and model capabilities with the U.S. government for review. The government’s stance was to start with limited access for vetted partners before gradually expanding availability.
The most delicate detail comes next. According to reports, under this mechanism, some clients seeking access must be approved by the government one by one. Altman also mentioned in an internal memo that the government would approve client access requests individually during the preview period.
One client, one review. This is a highly unusual scenario in the world of software distribution.
Think about our habits with online services over the years—register, pay, and use immediately. Even for expensive enterprise software, signing a contract grants access. When has it ever come to a company needing to wait in line for permits to use a tool?
Why is this happening? Broadly speaking, AI models are being treated as strategic resources for the first time.
Just two weeks ago, Anthropic’s Fable 5 was taken offline just three days after launch due to an export control directive, barring even their own foreign employees from accessing it. Now it’s OpenAI’s turn, with the government applying similar logic.
OpenAI’s attitude is interesting.
While cooperating, it included a fairly strong statement in its announcement.

The gist is that this government-mediated access process should not become a long-term default, as it blocks developers, businesses, and cybersecurity defenders who truly need top-tier tools.
In other words, I’ll tolerate it this time, but don’t expect this to continue.
It also seized the opportunity to make a request.

It hopes to work with the U.S. government to establish a clear, repeatable process rather than letting individual approvals become the industry norm. This step is crucial—the problem with vague power isn’t that it’s strict, but that it’s unpredictable.
What OpenAI wants is to transform unclear discretion into clearly written rules. It’s not seeking relaxation but certainty.
Half of the announcement focused on safety.
OpenAI has built a multi-layered defense system for the models, training them to reject dangerous requests. During generation, real-time classifiers monitor sensitive areas like networks and biology, pausing and escalating to larger models for review if something seems off. Violations are blocked before reaching you, and triggered accounts undergo account-level reviews.
Before release, it conducted over 700,000 GPU hours of automated testing, plus extensive external red-team exercises, while asserting that it hasn’t yet reached the highest danger level requiring a complete shutdown.
This rhetoric is half technical explanation, half a trust show for everyone—telling the government, and you and me, that it can manage this.
Ultimately, this is the most intriguing aspect of the release.
Anthropic’s Fable 5 was halted just three days after launch. OpenAI’s GPT-5.6 was restricted from the start to around twenty vetted partners, requiring government approval for each client.
In just half a month, the two strongest companies in the industry, with their strongest models, have both hit the same wall. This is no coincidence.
When one or two companies are regulated, it’s an isolated case. When two leaders, twice in a row, using the same logic, it’s a trend.
The core of this logic is that the U.S. government has begun treating frontier models as a category requiring special oversight. It even gave them a name—regulated frontier models—and is developing an assessment framework to match.
In other words, for models above a certain capability threshold, whether and how they’re released is no longer entirely up to the companies.
Why now?
Because this generation of models, for the first time, possesses capabilities that keep the U.S. government awake at night.
They can find software vulnerabilities on their own, assist in biological fields, and coordinate teams of sub-agents to perform dozens of steps continuously. These abilities are productive when used correctly but dangerous otherwise.
When a technology has both beneficial and harmful potential, regulatory intervention is almost inevitable.
So, we’re seeing a contradictory situation.
On the company side, there’s a desperate push to distribute models as widely as possible, since users, developers, and enterprises are their lifeblood.
On the government side, there’s a desire to hold back before full release, keeping national security in check. One side wants speed and breadth; the other wants stability and control. The clash of these forces has resulted in today’s phased, limited, and individually approved approach.
OpenAI’s statement is essentially an overflow of this contradiction. It dares not refuse to cooperate but is genuinely unwilling, so it complies while voicing that this shouldn’t become the norm.
Looking ahead, several trends may emerge.
First, phased releases could go from exception to norm.
In the future, any high-profile model reaching that capability threshold will likely start with limited access before gradual expansion. What seems unusual today may become commonplace in a couple of years.
Second, release authority could slowly become an invisible license.
Whether you get first access to the strongest models may soon depend on whether you’re on that vetted list. This means early adopters will gain a lead not through technical merit but through approvals, creating a time-based advantage unrelated to innovation.
Third, the battle over rules may matter more than the battle over capabilities.
OpenAI’s push to replace case-by-case approvals with repeatable processes reflects its desire to shape regulatory standards. Whoever can turn vague administrative discretion into clear, written rules will face fewer constraints in the next round.
The winner of this game may not be the company with the strongest model but the one most skilled at navigating regulation.
If you have any thoughts, feel free to join the discussion in the comments.
If you found this helpful, please like, share, and recommend the article. Follow "AI Robot Tea House."
-
![]()
Depreciation Rate on Par with Mobile Phones: Just 40% Value Retention After Three Years—Why Do Battery Electric Vehicles Lose Their Worth?
-
![]()
Clearing Bugatti Stock Worth 7 Billion: Why is Porsche 'Cutting Ties'?
-
![]()
Don’t Dismiss Huawei’s Potential in Sedans Just Because the Shangjie Hasn’t Hit It Big Yet
-
![]()
Unsold Cars in China Find Success Overseas
-
![]()
Ghosn: Only I Can Save Nissan, Shareholders Beg Me to Return
-
![]()
Expanding Automobile Consumption: It's Time to Address the High Cost of Electric Vehicle Repairs
-
![]()
Luna Ultra Entangled in 'National Subsidy Fraud' Controversy, Insta360 Pushed to the Brink by DJI
-
![]()
People have long suffered from splash ads. Will the 'temporarily disappeared' traffic behemoth make a comeback?







