ICML 2026 | One Model to Unify Humans, Objects, Sounds, and Actions: OmniShow Revolutionizes Multimodal Controllable Video Generation as a Systematic Engineering Feat!
 07/03 2026
07/03 2026
 500
500
Interpretation: The Future of AI-Generated Content
Humans, objects, sounds, and actions—when a video needs to simultaneously adhere to these four types of instructions, most solutions default to "each module handles its own part, then stitch them together." OmniShow takes a different path: it integrates visual injection, audio alignment, and training paradigms into a cohesive whole, transforming them from separate components into interlocking gears within the same machine. This work, a collaboration between The Chinese University of Hong Kong, ByteDance, Monash University, and The University of Hong Kong, has been accepted to ICML 2026.
This article starts with an overview: first, understanding what this "machine" aims to achieve, then examining how its three major innovations collaborate and complement each other to form a unified multimodal controllable video generation system. For more video demonstrations and comparative results, please visit the project homepage at https://correr-zhou.github.io/OmniShow.

OmniShow integrates multiple conditions into a single framework, enabling applications such as audio-driven avatars, object swapping, and video remixing.
The Challenge: Making Everything Work Simultaneously
The task at hand is Human-Object Interaction Video Generation. In a nutshell, it involves ensuring that four types of conditions are simultaneously satisfied in a single video: text prompts anchor the overall semantics and scene, reference images fix the identity of characters and the appearance of objects, audio drives mouth movements, expressions, and body rhythms, while pose provides frame-by-frame motion control. Its significance lies not in making the visuals more appealing but in transforming video into a content asset that can be precisely orchestrated by multiple conditions, directly applicable to e-commerce live streaming, short video narration, digital human explanation and interaction, and entertainment.
The difficulty lies precisely in the word "simultaneously." Existing approaches each excel in their own domain but are mutually incompatible: R2V maintains reference appearance well but often ignores audio; A2V can be driven by audio but often only recognizes the first frame, struggling to specify both character and object simultaneously; pose-guided methods excel at controlling motion but fail to preserve identity and audio-visual synchronization under complex interactions; some HOI methods even require additional inputs like masks, trajectories, depth maps, and bounding boxes, significantly raising the barrier to entry. Cascading these subsystems together results in a bloated architecture prone to failure at the interfaces. OmniShow's approach is straightforward: instead of assembling pieces, train a single model within an end-to-end framework to learn collaboration.
It categorizes the obstacles to "unification" into three types—balancing controllability and visual quality, scarcity of comprehensive data, and lack of systematic evaluation—and addresses them one by one through three main strategies, building upon Waver 1.0 (a 12B MMDiT video generation model). The key to understanding the entire system lies in one principle: without disrupting the base model's generative priors, place each condition in its most appropriate position.
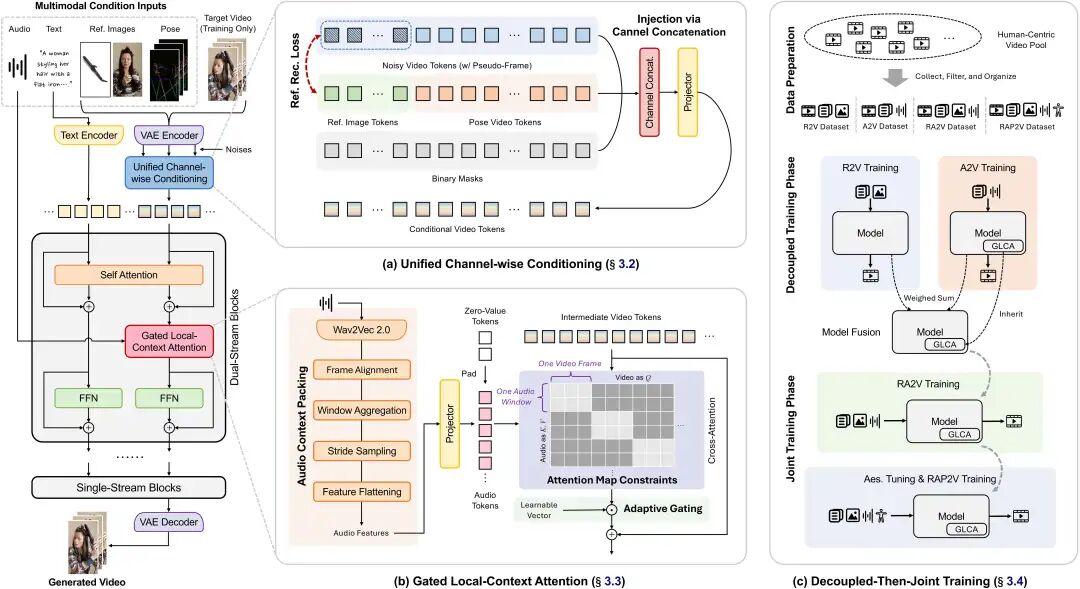
OmniShow's Complete Pipeline: Visual Condition Injection, Audio Local Alignment, and Phased Joint Training Work in Tandem
Gear One: Visual Conditions, Integrated Naturally Through Native Interfaces
Reference images and pose are both visual signals but serve different purposes—the former anchors appearance, while the latter imposes frame-by-frame motion constraints. OmniShow reuses Waver 1.0's native channel-concat mechanism to unify their access: after VAE encoding, pseudo-frame tokens are added in the temporal dimension specifically to carry reference information, while pose is aligned with noisy video tokens. As a result, the model's input format remains nearly identical to its native I2V setup, minimizing the task adaptation gap. On top of this, a Reference Reconstruction Loss is introduced: pseudo-frame tokens are initialized from noised reference tokens at the same timestep and are required to reconstruct their semantic details, turning "fidelity" from a passive constraint into an active goal pursued by the model.

Leveraging the native channel-concat interface to incorporate reference images and pose seamlessly, rather than building separate pathways
Gear Two: Audio Conditions, Aligned Locally with a Dedicated Mechanism
Sound is a continuous, rhythmic modality; forcing it into the channel would disrupt synchronization. OmniShow designs a dedicated Gated Local-Context Attention for audio: multi-layer features are first fused using Wav2Vec 2.0, then aligned to video fps via a sliding window (window=5, stride=4), while masked attention ensures each latent frame only attends to corresponding local audio tokens, establishing strict frame-wise audio-visual correspondence. The accompanying Adaptive Gating initializes the gating vector to near-zero, allowing audio's influence to grow steadily without immediately disrupting the visuals.
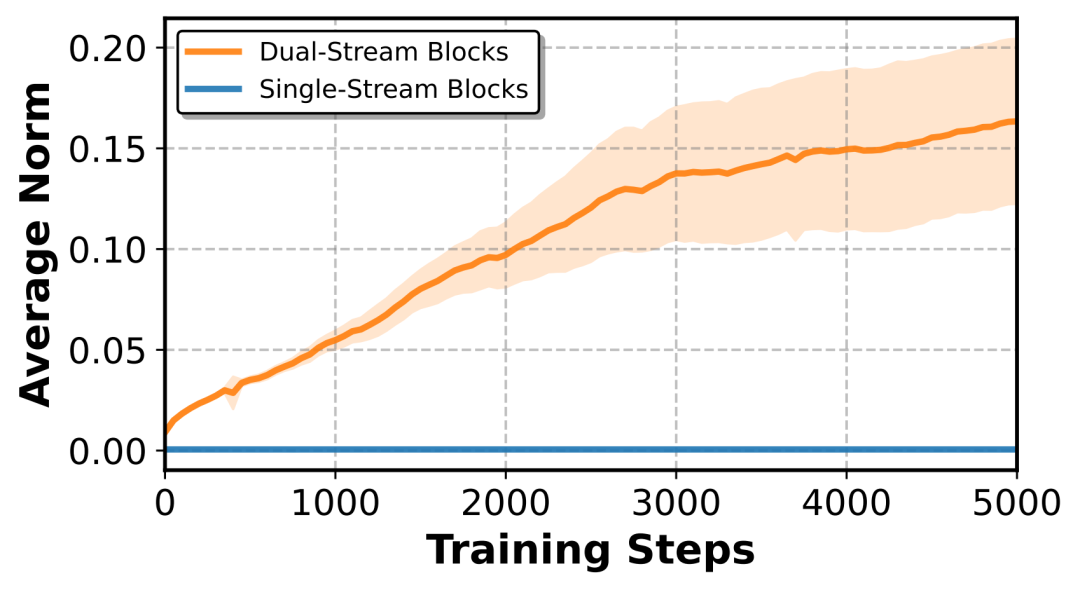 Adaptive Gating visualizes the strength of audio signals' influence across modules, guiding efficient injection
Adaptive Gating visualizes the strength of audio signals' influence across modules, guiding efficient injection
More cleverly, the gating vector doubles as a "probe": by observing gate norms, the team discovered that audio influence concentrates in dual-stream blocks, so injection is limited to those layers. The cost is minimal—the model increases by only ~2.5%, totaling 12.3B; in contrast, HuMo pays +21.4% for audio, reaching 17B.
Gear Three: Training Paradigm, Cultivating Specialists Before Fusion
Complete HOIVG samples are extremely scarce—a single sample must simultaneously meet the quality standards of text, reference images, audio, pose, and the target video, making them rare finds. OmniShow constructs a multi-layer heterogeneous data pipeline to leverage fragmented data from R2V, A2V, RA2V, RAP2V, and more: starting from a large pool of human-centric videos, it applies shot segmentation, then filters layer by layer based on resolution, aesthetics, motion intensity, OCR, and other dimensions.
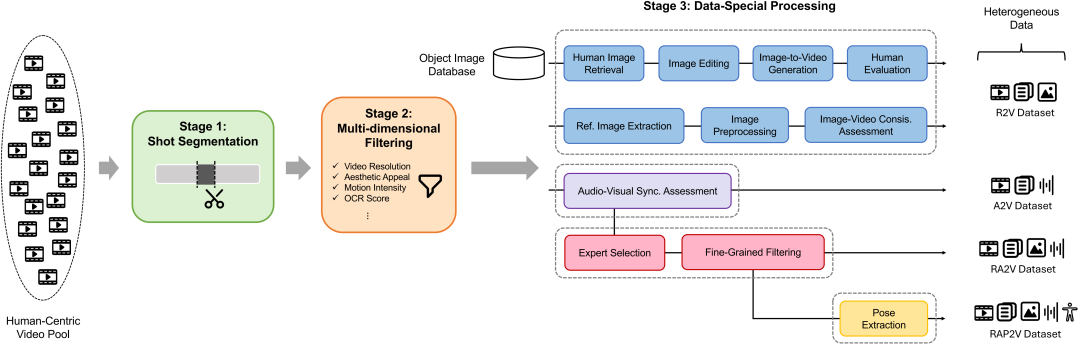 From video segmentation to multi-dimensional filtering, ultimately organizing diverse heterogeneous training materials
From video segmentation to multi-dimensional filtering, ultimately organizing diverse heterogeneous training materials
Training employs Decoupled-Then-Joint Training: first, train R2V and A2V as specialists separately, then merge them via weight interpolation (audio modules taken from A2V, others fused at A2V/R2V = 0.6/0.4), followed by continued training on complete RA2V, with pose introduced last. Surprisingly, even before explicit RA2V training, the merged model already exhibits joint reference-audio capabilities—controllability emerges spontaneously through weight merging.

After merging expert models, joint reference-audio generation capabilities emerge even without dedicated RA2V training
The Fourth Piece: Incorporating Evaluation into the System
To prove that the three gears truly collaborate rather than hinder each other, a unified benchmark is needed. The team constructs HOIVG-Bench: 135 carefully selected samples, each equipped with detailed captions, character and object references, semantically aligned audio, and coherent pose sequences, scored across five dimensions—Text Alignment, Reference Consistency, Pose Accuracy, Audio-Visual Synchronization, and Video Quality—to specifically expose issues like "accurate pose but drifting identity" or "aligned mouth but distorted product."
 Statistical distribution and examples from HOIVG-Bench, covering multi-conditional inputsAfter the gears interlock, the results speak for themselves
Statistical distribution and examples from HOIVG-Bench, covering multi-conditional inputsAfter the gears interlock, the results speak for themselves
Qualitatively, OmniShow maintains stable identities, natural motions, and synchronized audio-visuals across various condition combinations—a clear sign of "synergy" rather than "compromise."
 Qualitative comparisons under multiple condition combinations show consistent stability in identity, motion, and audio-visual synchronization
Qualitative comparisons under multiple condition combinations show consistent stability in identity, motion, and audio-visual synchronization
Quantitative results are analyzed under three settings. Under R2V settings, OmniShow leads with a NexusScore of 0.389, surpassing VACE (0.368) and Phantom-14B (0.366); its FaceSim of 0.874 closely matches the larger Phantom-14B (0.876) and tops AES (0.468), VQ (11.12), and MQ (5.885). Under RA2V settings, it achieves Sync-C 8.612 and Sync-D 7.608, outperforming HuMo-17B's 8.013/8.316, with FaceSim 0.810, NexusScore 0.369, AES 0.465, VQ 10.86, and MQ 5.554—showing simultaneous improvements in audio-visual synchronization, character-object consistency, and visual quality after adding audio. Under RP2V settings, AKD drops to 0.174, PCK rises to 0.460, demonstrating significantly better motion control accuracy than VACE (0.206/0.336), while maintaining leading NexusScore (0.418) and VQ (10.28). All this is achieved by a mere 12.3B model, with the audio module adding only ~2.5%—a testament to the cost-effectiveness of "systemic synergy."
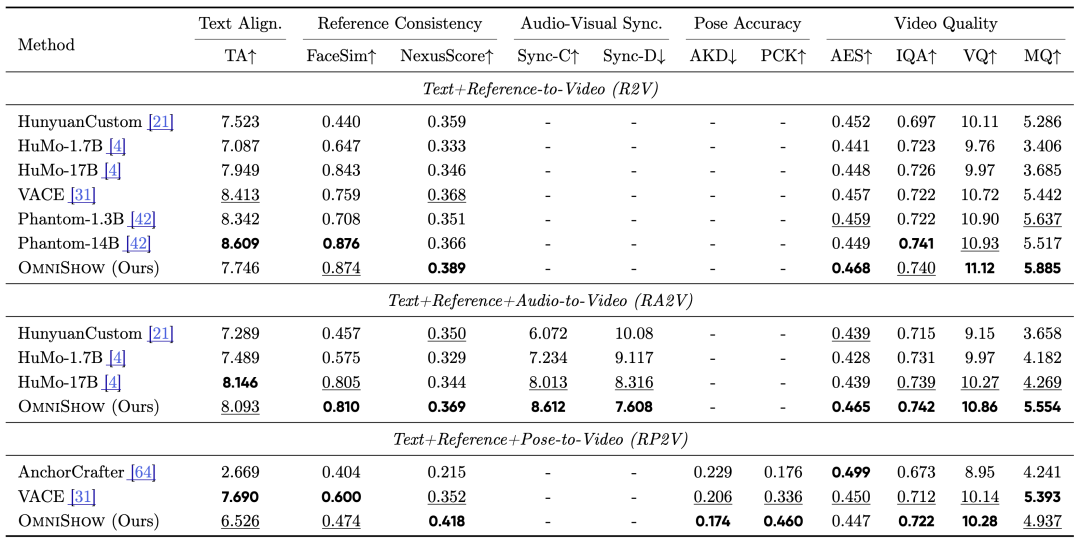 Main experimental results from HOIVG-Bench, covering R2V, RA2V, RP2V, and other condition settings
Main experimental results from HOIVG-Bench, covering R2V, RA2V, RP2V, and other condition settings
It is worth mentioning that being integrated into a unified framework does not weaken individual specialties. On the EMTD benchmark specifically designed for evaluating audio-driven capabilities, OmniShow-A2V achieved Sync-C 6.49, AES 1.51, and IQA 2.26, ranking second only to Hallo3. This path of "strengthening specialties first before integrating them into the system" does not sacrifice the core capabilities of audio-driven technology itself.
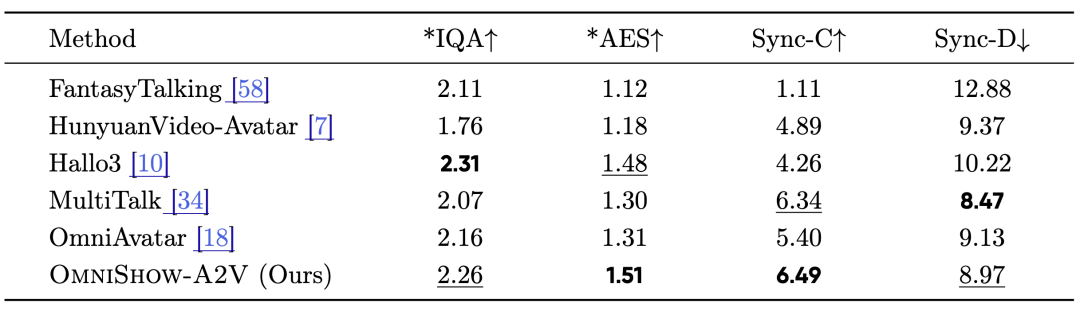 The results of OmniShow-A2V on the EMTD benchmark confirm that its audio-driven capabilities remain solid.
The results of OmniShow-A2V on the EMTD benchmark confirm that its audio-driven capabilities remain solid.
How many play modes can a system extend into?
Since the four types of conditions are incorporated into the same framework without interfering with each other, they can be freely combined: pairing a character reference with audio creates an audio-driven avatar; pairing an object reference with a pose enables object swapping; reassembling people, objects, sounds, and actions results in video remixing.
 The unified framework extends into broader applications such as audio-driven avatars, object swapping, and video remixing.
The unified framework extends into broader applications such as audio-driven avatars, object swapping, and video remixing.
The three major innovations, while seemingly operating independently, actually share a common engineering philosophy: understanding the foundation, expanding organically, placing each condition in the right position, and then interlocking them into a cohesive whole. As multimodal controllable video generation transitions from a "bonus feature" to a necessity for content production, what is truly scarce is not another single-point model but a machine capable of simultaneously accommodating people, objects, sounds, and actions while making them work in harmony—OmniShow provides precisely such a complete systemic solution.
References
[1] OmniShow: Unifying Multimodal Conditions for Human-Object Interaction Video Generation
-
![]()
Rokid's Ambition and Embarrassment: 300,000 Sales Can't Support Its Ecosystem Dream
-
Are Gaming Ventures No Longer in Vogue Among Tech Titans?
-
![]()
Kuaishou’s Keling AI, Valued at $18 Billion with a Five-Year IPO Pledge, Faces a Make-or-Break Challenge
-
![]()
Valued at $18 Billion with a Five-Year IPO Plan: Kuaishou’s Kling AI Takes a Bold Leap
-
![]()
NVIDIA Launches 'Computing Power Financing'
-
![]()
Following Up on the 'Safety Net' for Intelligent Driving: Is Huawei's Strategy Astute or Perilous?
-
![]()
ICML 2026 | One Model to Unify Humans, Objects, Sounds, and Actions: OmniShow Revolutionizes Multimodal Controllable Video Generation as a Systematic Engineering Feat!
-
![]()
Mid-Year Sales Analysis: Leapmotor Faces Challenges Alone, NIO Breaks Free from the 'NIO 30K' Stigma