Alibaba and ByteDance "Hunt" for Zhipu and MiniMax: Who Should Determine Token Pricing?
 04/15 2026
04/15 2026
 575
575

Not long ago, Anthropic stopped allowing subscribed users to access the Claude API through third-party tools like OpenClaw. The reasoning was straightforward: running an OpenClaw agent for a day consumes computing power costing between $1,000 and $5,000, while users only paid $200 monthly.
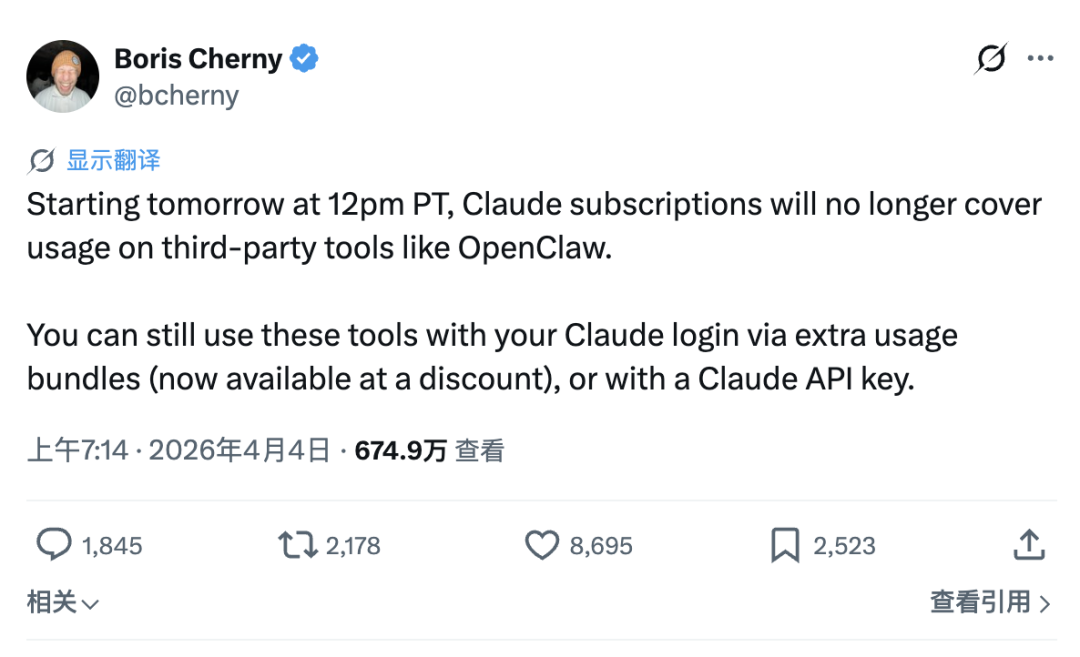
Boris Cherny, head of Claude Code, stated in the announcement that the subscription service was “not designed for the usage patterns of these third-party tools.” While true, this obscures a more fundamental issue: no subscription service can be designed to cover such usage patterns. Token consumption in Agent scenarios has no upper limit and lacks historical data for reference, making any fixed monthly fee a guess about an unmodelable variable.
In late March, China’s National Data Bureau released another set of figures: China’s daily average Token calls surpassed 140 trillion, a thousandfold increase in two years. During the same period, ByteDance’s Token calls ranked among the top three globally, alongside OpenAI and Google. Xia Lixue, CEO of Wuxin Qiong, described this growth at an industry forum, saying the last time he saw a similar curve was when mobile data usage surged from 100MB per month during the 3G era. Back then, no one anticipated the rise of Douyin, WeChat, and food delivery services after data caps were lifted.
Together, these two events describe the same reality: Token consumption is growing at an unprecedented rate, yet the pricing logic supporting the entire industry remains rooted in assumptions from the chatbot era two years ago—namely, that user consumption can be predicted by historical data, light users will naturally offset heavy users, and overall costs can be averaged out.
Intelligent agents have shattered every premise of this assumption. The pace of market change has outstripped the responsiveness of any pricing model. Over the past two years, the evolution of the Token market has been driven by a single logic: when competitors can replicate advantages—scale can be caught up, algorithms can be open-sourced, and scenarios can be overwhelmed by large platforms’ distribution capabilities.
Currently, the only capability difficult to replicate quickly is the internalization of Token efficiency into product architecture, pricing logic, and engineering culture. Among all players, only Anthropic has truly systematized this approach.
The Meaninglessness of Average Pricing
Tokens differ from traditional production factors like electricity and steel due to their unique “programmability.” No traditional production factor can alter its value by a factor of 100,000 simply through different “instructions.” This programmability is the essential characteristic of Tokens as a new production factor and the key to understanding the current chaos in the AI economy.
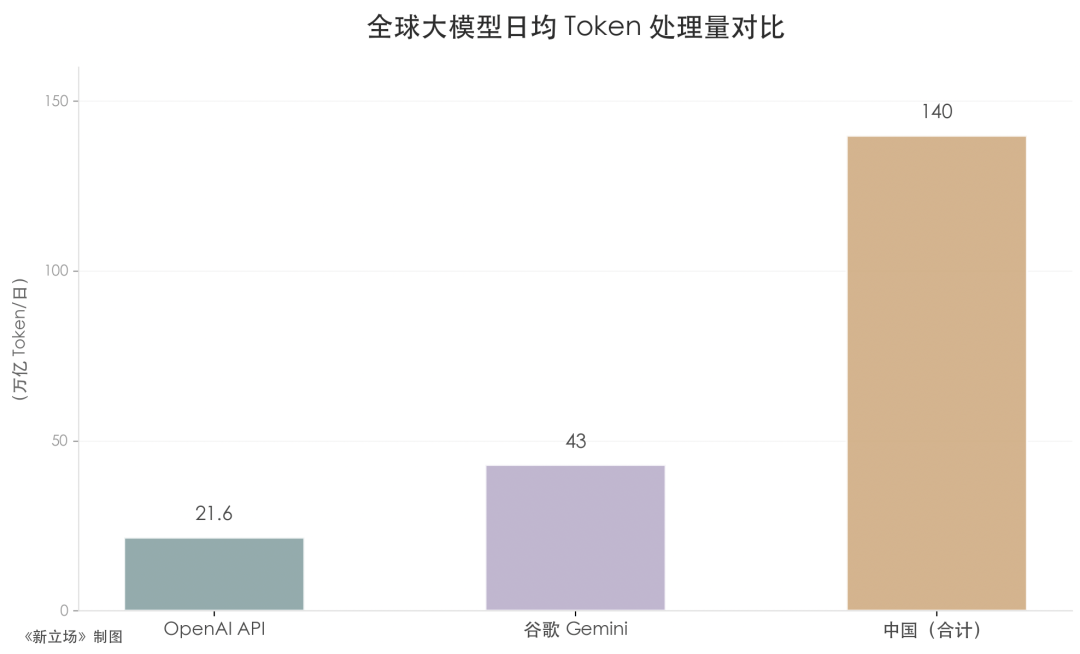
To grasp this, one must first develop a sense of scale. 36Kr reported that OpenAI’s API processes approximately 21.6 trillion Tokens daily, Google’s Gemini processes about 43 trillion, while China’s 140 trillion is more than double their combined total. JPMorgan predicts that China’s AI inference Token consumption alone will increase 370-fold in five years. This scale indicates that Tokens have become an economic indicator.
Moreover, a significant portion of Token consumption occurs outside public cloud statistics. Financial institutions run invoice recognition on local servers, in-car intelligent cockpits process conversations within the vehicle, and industrial robots’ vision models operate on edge devices with millisecond-level responses—none of which appear in public data. One industry insider estimates that non-public cloud API calls are at least five to ten times those of public clouds.
Beyond scale, the value structure and production costs of Tokens warrant attention. In March, Jensen Huang dissected the AI industry into five layers in a bylined article: energy, chips, infrastructure, models, and applications. He defined Tokens as the fundamental unit of modern AI, its language, and currency. The brilliance of this definition lies in its dual reference to Tokens’ attributes: as a language, they are the atoms of computation; as a currency, they are the medium of value exchange.
However, the cost of producing a Token is far more complex than this definition suggests. According to Sam Altman and Epoch AI, ChatGPT consumes approximately 0.3 watt-hours per text prompt. Google Search, by contrast, uses only 0.03 watt-hours. In 2025, Google disclosed that Gemini consumes about 0.24 watt-hours per typical text prompt and generates roughly 0.03 grams of CO2.
As model complexity increases, inference costs rise accordingly. A GPT-5-level system may consume approximately 18 watt-hours per query and up to 40 watt-hours during extended reasoning. The gap arises from two factors: model size (more parameters require greater computation per Token) and reasoning mode (new-generation models perform extensive implicit reasoning internally before outputting each visible Token, amplifying the true cost of a single visible Token).
This is the fundamental difference between Tokens and production factors like electricity or oil: a Token’s value is determined not by production cost but by usage scenario. A million Tokens used for casual chat may be worth $0.01; for code generation, $200; for legal document review, over $1,000—a value gap of 100,000 times. Yale researchers describe this as Tokens’ “contractable” attribute: quantity can be precisely measured, but value depends on what they are programmed to do.
When the entire industry applies a single pricing logic to usage scenarios with a 100,000-fold value gap, systemic pricing chaos is not accidental but inevitable.
Thus, the so-called average Token price is as meaningless as describing a business district with both street vendors and Michelin-starred restaurants by average spending per customer. Collis and Brynjolfsson estimated in 2025 that generative AI created approximately $97 billion in consumer surplus for U.S. consumers in 2024 alone, with users deriving far more value than they paid. The vast majority of this value concentrated in high-value application scenarios.
The Closing Window of the Token Economy
In the Token economy, competitive advantage hinges on time windows shaped by technological leaps, product transformations, and market structures. The beneficiaries of each window unknowingly pave the way for the next disruptor, and players who consistently secure positions across multiple windows are the true winners.
In early 2025, algorithms were the first window. After DeepSeek V3’s release, the Mixture of Experts (MoE) architecture reduced inference costs for equivalent capabilities by an order of magnitude: the model contains multiple expert submodules, activating only a small portion per inference, drastically compressing actual computation while retaining full model capabilities.
However, the paradox of the algorithm window is that the key to opening it also locks it shut. DeepSeek chose open-source, releasing core model weights and architectural designs to attract global developers into its ecosystem. This choice rapidly expanded market share in the short term but actively compressed the algorithm’s leading window in the medium to long term. When architectural innovations are open-sourced, the industry’s Token cost baseline resets, turning algorithmic advantages from proprietary barriers into public infrastructure.
By year-end, scale became the second window. Volcano Engine adopted tactics from internet traffic wars, using massive airport advertisements to announce its presence in the Token market. Tan Dai, sharing the latest business progress on April 2, mentioned that Volcano Engine’s Token calls grew 1,000-fold within two years, with trillion-Token-consuming enterprises increasing to 140.

Yet scale advantages have a limited lifespan. In an interview with Yicai, Tan Dai also noted that much of the massive Token consumption involved inefficient computing. Using math problems as an example, he explained that enumeration methods require high computation; models lacking capability resort to such approaches, leading to unnecessary waste. Superior models find concise solutions, offering significant optimization potential. Behind scale numbers lies substantial avoidable computing waste. When competition shifts from “how much is consumed” to “how much value each Token creates,” the scale window begins to close.
Scenarios are currently the most fiercely contested area in Token competition. Zhipu, MiniMax, and Yuezhi’an lack ByteDance’s traffic scale or Alibaba and Tencent’s cloud ecosystems but have found footholds in high-value B2B scenarios. Zhipu and MiniMax once surpassed traditional internet companies like Kuaishou in market value, demonstrating the immense Premium valuation (valuation premium) scenario windows can create at specific stages.
But this window is now narrowing. At an industry forum, Yang Zhilin asked Zhipu CEO Zhang Peng: “Why did you raise prices?” Zhang Peng replied that completing an Agent task consumes 10 to 100 times more Tokens than answering simple questions; long-term reliance on low-price competition harms the entire industry.
Behind this dialogue, a larger scenario battle is unfolding. ByteDance embeds large model capabilities directly into enterprise collaboration workflows and massive traffic nodes via Feishu and Coze platforms. Tencent leverages the WeChat ecosystem and Enterprise WeChat to control the shortest social pathways for businesses to reach and serve customers. Alibaba has consolidated its AI businesses into the ATH Group, packaging Token consumption as part of enterprise digital infrastructure.
These three companies possess long-established trust relationships and system integration capabilities at the enterprise level. The scenario advantages independent vendors rely on—maintained through model quality differences—are rapidly being compressed by such structural advantages.
Token efficiency is the fourth emerging window and the hardest to replicate quickly. Competition in this window currently centers on coding scenarios. After Anthropic banned third-party tools, users accustomed to low-cost Claude access began seeking alternatives. OpenAI quickly positioned itself as a more user-friendly option. However, Anthropic is betting on training and model runtime efficiency, while OpenAI assumes Altman can always secure more funding to support computing scale.
Using capital to stack computing power for market share is a viable but unsustainable strategy. By late March, OpenAI’s API processed over 15 billion Tokens per minute, up from 6 billion in October 2025. Yet computing supply growth lags far behind, with GPU lease prices rising 48% in two months. NVIDIA’s latest Blackwell chip now costs $4.08 per hour to rent, and data center construction cycles span years. OpenAI even partially suspended Sora, its video generation tool, to allocate computing resources to coding and enterprise products.
Anthropic focuses on Harness Engineering, redesigning Agent scheduling architectures to reduce invalid Token consumption systemically, achieving more with less computing power. This redefines efficiency under the reality of computing scarcity.
In China, Alibaba Cloud is also entering the efficiency window, integrating Token pricing, call tracking, and enterprise billing management into a unified cloud infrastructure. Wu Yongming noted that many enterprises now treat Token consumption not as IT budgets but as production materials and R&D costs. This is a slower approach but harder to disrupt.
With computing supply hitting physical limits and demand accelerating, what is truly scarce is not cheap Tokens but Tokens that produce the highest value density under constrained computing power.
The Ban on OpenClaw Is Just the Result
Under the Multiple pressures (multiple pressures) of computing scarcity, ineffective pricing systems, and uncontrolled Agent consumption, Anthropic is the only company so far that has not merely adjusted pricing strategies but also redefined “how Agents should operate” at the engineering architecture level. The ban is a passive response; Managed Agents are the proactive answer.
Harness is the scheduling layer of the Agent framework, responsible for deciding when to invoke models, how to manage context, and how to handle errors. In the Chatbot era, this logic was relatively simple. Entering the Agent era, Harness began handling more complex tasks, generating substantial unnecessary Token consumption.

The Anthropic engineering blog provides a specific case: Claude Sonnet 4.5 exhibited a behavior referred to by engineers as 'context anxiety,' where the model would prematurely terminate tasks when it sensed the context window approaching its limit. To address this, Harness introduced a context reset mechanism that forcibly clears and reloads the context at appropriate times to ensure task continuation. At the time, this was a reasonable engineering fix.
The issue arose after the release of Claude Opus 4.5. The new model no longer experienced 'context anxiety,' but the old reset mechanism continued to trigger with every execution, consuming unnecessary tokens and introducing unnecessary latency. These mechanisms, once patches to solve problems, became a cost burden. Anthropic engineers referred to this as 'dead weight.'
This represents a structural flaw in the Harness framework: each Harness is a snapshot of a model's capabilities at a specific moment. While models continue to evolve, the snapshot is treated as a permanent rule. The faster the model iterates, the more severe this misalignment becomes.
In commercial scenarios, this problem is further amplified. When processing a single user query, OpenClaw generates several times more API requests than the official Claude Code framework, with each request carrying a context window exceeding 100,000 tokens. When converted to API rates, the true cost of a single query becomes dozens of times higher than the subscription price. Regardless of an individual's subjective usage frequency, requests initiated through such frameworks inherently carry the cost profile of heavy users. Platform subsidies for heavy users thus shift from a probabilistic issue to a deterministic one.
Anthropic's response is Managed Agents, with the core idea being to establish a stable interface for the Agent domain, enabling an abstraction layer that allows for free substitution. With 'context anxiety' eliminated, the corresponding reset mechanism naturally phases out, leaving no 'dead weight.' Internal test data shows that in structured file generation tasks, Managed Agents improved task success rates by up to 10 percentage points, with the most significant improvements seen in the hardest tasks.
The Hermes Agent, which emerged around the same time, corroborates this judgment from another direction. This framework, emphasizing a 'closed-loop learning cycle,' chooses to write updates to accumulated operational procedure files in a patch-based manner, transmitting only the specific fields requiring modification rather than rewriting the entire file. Patches touch only the problem areas, resulting in lower token consumption. This represents one of the most concrete manifestations of token efficiency awareness at the framework design level.
The new competition in the token economy has become nuanced to the point of 'who can extract higher value from every token.' Luo Fuli wrote at the end of her post, which has garnered over 730,000 views, that the real solution lies not in cheaper tokens but in the co-evolution of models and Agents.

This statement refers not only to technical routes but also to the necessary transformation in the industry's pricing logic: shifting from volume-based billing to value-based pricing, and from cost management to result creation. This is a transformation the entire industry needs to accomplish.
Anthropic's exploration of the Harness architecture provides the clearest direction to date. However, the journey ahead remains long.
*The featured image and illustrations in the text are sourced from the internet.
-
![]()
AI Giants Start Borrowing to Fuel Computing Power Race
-
ByteDance Initiates Largest B2B Structural Adjustment, This Time It's Truly Different
-
![]()
Let's Talk About Kingsoft Office's Mid-Year Outlook and the True Strength of Its AI-Powered Office Solutions
-
Despite 150 Million Users, Struggles Persist: AIShige Faces Tough Competition from Seedance and Kling in AI Video Monetization
-
![]()
Ensuring Safe Gear Shifting in the Automotive Industry: Transitioning from 'Product Oversight' to 'Full-Chain Governance'
-
![]()
Net Profit Soars to $133.7 Billion! Azure Revenue Tops $100 Billion, with AI Fueling Microsoft's Growth
-
![]()
Before 6G Hits the Market, the U.S. Forges a 'Rules Alliance': What Challenges Await Chinese IoT Enterprises?
-
![]()
Intelligent Driving's 'Little Blue Light' Faces Ban: Night Glare and Cut-in Risks Prompt Official Action





