Why Occupancy Networks Enhance Autonomous Driving Perception
 01/19 2026
01/19 2026
 627
627
The progression of autonomous driving technology is essentially a quest to equip machines with the ability to 'comprehend the geometric structure of the physical world.' Historically, perception systems heavily depended on the 'classification and recognition' of specific objects. If the system encountered a vehicle or pedestrian type present in its training set, it could pinpoint them on the road by enclosing them in two-dimensional or three-dimensional bounding boxes. However, this approach, rooted in object recognition, started to falter when confronted with the myriad of 'unusual' obstacles encountered in the real world.
To overcome this limitation, perception algorithms have pivoted from object recognition to spatial perception. The occupancy network, an algorithm born out of this necessity, shifts focus from identifying what an object 'is' to determining whether a space 'is occupied.' This perspective change not only elevates perception from a 2D to a 3D dimension but also significantly bolsters the generalization capabilities and safety of autonomous driving systems.
Why Must Autonomous Driving Comprehend 'Space'?
In the nascent stages of autonomous driving perception, the 'HydraNet' architecture was predominantly employed, utilizing multi-camera fusion and Transformer technology to translate 2D images into a 3D perception of the surrounding environment. Despite its ability to generate bird's-eye view (BEV) perception, this method was still constrained by the 'box' model.
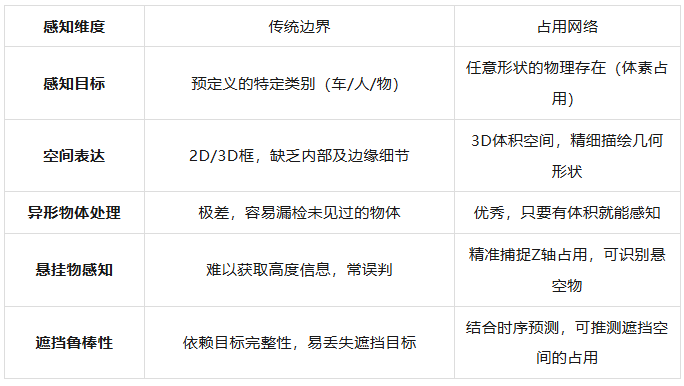
Traditional perception systems often envelop targets in regular rectangular prisms. However, real-world objects exhibit highly irregular shapes, such as cranes with elongated booms, uniquely shaped flatbed trucks laden with cargo, or common road obstacles like scattered cardboard boxes and discarded tire treads. If a model is solely trained to recognize cars and trucks, it might overlook unfamiliar, irregularly shaped obstacles due to an inability to classify them. This issue, known as perception miss, is frequently discussed within the industry.
Furthermore, early BEV perspectives primarily concentrated on lateral and longitudinal ground spaces, neglecting crucial height information along the Z-axis. This makes it challenging for vehicles to make accurate judgments when encountering semi-airborne objects, such as overpass edges, height limit bars, or tilted utility poles.
The occupancy network tackles this challenge by segmenting the world into minute voxels, akin to pixels in 3D space. The system predicts whether each voxel is 'free' or 'occupied.' This volume-based perception method not only accurately discerns differences in object motion states but also captures intricate geometric structures. Essentially, the occupancy network endows autonomous vehicles with a form of 'spatial intuition.' Even if the system doesn't recognize the object ahead, as long as it occupies space, the system can perceive its physical presence and avoid it.
Advantages of Occupancy Networks Over Traditional Bounding Box Perception
This transition from 'object-oriented' to 'space-oriented' perception mirrors the occupancy grid mapping concept in robotics within the deep learning era. It eschews a perfect interpretation of object semantics in favor of an accurate grasp of the physical world's geometric continuity. This strategy exhibits robust resilience when dealing with 'edge cases,' as physical laws remain constant regardless of external environmental changes—entities must occupy space.
The Architecture Underlying Occupancy Networks
To support such a massive real-time 3D perception task, the neural network architecture behind the occupancy network is exceedingly complex. Taking Tesla's technical solution revealed at AI Day 2022 as an example, the process commences with an efficient backbone network (such as RegNet) and a feature fusion module (such as BiFPN), which extract high-dimensional 2D image features from multiple surround-view cameras. Subsequently, the model introduces a spatial attention mechanism and utilizes spatial queries with 3D spatial location information to perform cross-camera fusion among the image features generated by multiple cameras. This process can be viewed as a mathematical dimensionality upgrade, reconstructing discrete, distorted 2D image data into a unified 3D vector space.
Within this 3D vector space, the system incorporates temporal fusion to manage dynamic environments. Tesla's solution employs two sets of feature queues. The temporal feature queue updates features every 27 milliseconds to capture the continuity of fast-moving targets, while the spatial feature queue updates based on the fixed distance traveled by the vehicle. This is particularly crucial when the vehicle is stationary, such as waiting at a traffic light, to prevent the model from 'forgetting' previous spatial information due to inactivity. To integrate this temporal information, a spatial recurrent neural network (Spatial RNN) module organizes the hidden state into a 2D or 3D grid, continuously updating the 'memory' of the surrounding environment as the vehicle moves.
During the decoding stage, the occupancy network doesn't merely output a voxelized map. To overcome the limitation of fixed resolution, the model introduces an implicit coordinate query (Implicit Queryable MLP Decoder). This means that for any coordinate (x, y, z) in space, the model can decode multiple types of information about that point. This design grants the perception system exceptional flexibility, enabling it to provide both a broad panoramic perception and high-density fine-grained sampling in critical areas.
In addition to Tesla's approach, variants like OccNet and TPVFormer have also emerged. OccNet employs a cascaded voxel decoder, which doesn't generate high-resolution 3D volumes all at once but gradually enriches height information and voxel details through multi-level refinement, balancing computational efficiency and perception accuracy. It also utilizes a 3D deformable attention mechanism optimized for 3D space, resulting in significantly improved mean intersection-over-union (mIoU) performance in handling small obstacles like pedestrians and traffic cones compared to traditional BEV methods.
To further enhance perception accuracy, domestic manufacturers such as Li Auto and Huawei have opted for a deep fusion of vision and LiDAR. Li Auto's BEV fusion algorithm integrates high-precision ranging data from LiDAR with the rich semantic information collected by cameras. LiDAR can detect hazardous targets up to 200 meters away in advance and employs intelligent noise filtering algorithms to identify environmental noise such as rain, fog, and exhaust from preceding vehicles. Its reaction speed is typically just 0.1 seconds, far surpassing the 0.6 seconds of human drivers. Under this fusion architecture, the occupancy network gains stronger robustness. Even if cameras fail in darkness, tunnel smoke, or extreme weather, the spatial occupancy information generated based on LiDAR point clouds can still ensure the normal triggering of safety functions like automatic emergency braking (AEB).
The following table compares the differences in the implementation paths of mainstream occupancy network technologies:
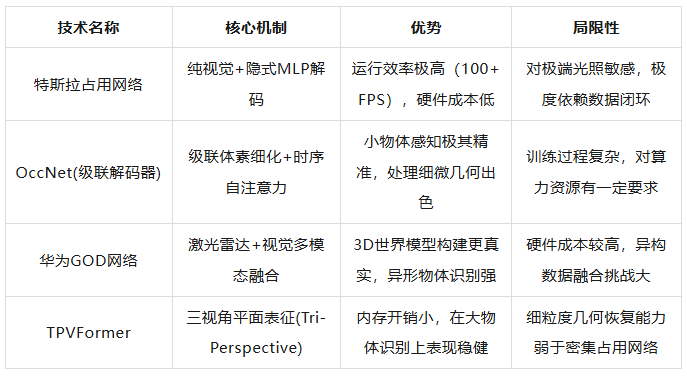
Behind the evolution of these algorithms lies a trade-off between 'computational cost' and 'information density.' Although 3D voxels can provide the richest information, if space is divided too finely, the computational load will increase exponentially. The emergence of technologies like implicit queries and cascaded decoding aims to achieve high-quality reconstruction of the 3D world with limited in-vehicle computational power.
How Occupancy Networks Revolutionize Vehicle 'Brain Decision-Making'
If perception is the 'eyes' of autonomous driving, then planning and control (PnC) are the vehicle's 'brain.' Historically, there was a significant gap between perception and planning and control. Perception output a plethora of noisy labels, while planning and control relied on a set of hard-coded logical rules. The introduction of the occupancy network bridges this gap through a 'unified representation' approach. Since the occupancy network directly outputs the geometric occupancy state of the physical world, the planning model can utilize this data to generate a cost map without the need for complex intermediate conversion layers.
In local path planning, the system must evaluate the safety of tens of thousands of candidate trajectories. The traditional method involves performing collision detection for each recognized object, which is time-consuming at congested intersections with numerous objects. Based on the occupancy network, the planner can employ a spatiotemporal occupancy grid map (SOGM) to predict the state evolution of the surrounding space over a short period. This prediction isn't a simple linear extrapolation but incorporates the motion flow information of objects, accurately predicting the movements of pedestrians or vehicles cutting in. By sampling trajectories in the Frenet coordinate system and combining them with a dynamic occupancy map for real-time evaluation, the vehicle can select an optimal path that is both comfortable and safe.
A deeper transformation brought about by the occupancy network lies in the 'physicalization' of planning algorithms. Some technical solutions propose embedding the artificial potential field method (APF) as a physics-inspired guide into the training of neural networks. This means that the predicted occupancy map must not only align with visual features but also adhere to physical laws. For instance, objects cannot instantaneously displace, and two entities cannot occupy the same space simultaneously. Incorporating these physical constraints results in smoother trajectories generated by planning, more in line with human driving intuition. In complex urban environments, the system can even utilize the soft actor-critic (SAC) algorithm to learn how to handle unpredictable obstacle behaviors through multi-channel cost map observation (M-COST), enabling real-time adaptive planning in dynamic environments.
Furthermore, the continuous geometric representation generated by the occupancy network (such as the neural signed distance field, ONDP) provides millimeter-level accuracy for obstacle avoidance. This high-precision geometric feedback is crucial for navigating through narrow spaces. By performing differentiated distance queries, the planner can swiftly calculate the gradient information between the vehicle's edges and the nearest obstacles, guiding the control system to make minor steering corrections. This has significant application value in automatic parking or navigating through narrow alleys.
The empowerment of the planning and control system by the occupancy network is mainly reflected in the following aspects:
Unified input source: Static road structures (such as guardrails and curbs) and dynamic obstacles (pedestrians and vehicles) are unified in the same voxel space, eliminating error accumulation caused by cross-module processing.
Decoupling of prediction and perception: The flow information output by the perception module directly contains the speed and motion trends of objects, making short-term predictions (usually within a 2-second time horizon) by the planning module more accurate.
Safety closed loop: Through physics-inspired learning, the system can identify the boundaries of 'impassable areas' and ensure that the vehicle maintains a sufficient safety margin, even if these areas are composed of unclassified, irregularly shaped objects.
This fusion of perception and planning and control is the necessary path for end-to-end autonomous driving. In Tesla's FSD V12 architecture, the 3D spatial understanding provided by the occupancy network serves as the underlying foundation, supporting a single deep learning model that achieves direct mapping from raw image input to driving command output. This architecture no longer relies on millions of lines of human-written rules but automatically learns driving strategies in complex spatial environments by studying the behavioral data of a vast number of excellent human drivers.
Industrial Implementation and Future Prospects
Although the occupancy network is theoretically highly appealing, it faces dual challenges of data annotation and real-time computational power in large-scale industrial implementation. In the era of traditional perception, manually annotating obstacles with bounding boxes was feasible, but classifying and annotating every voxel in 3D space clearly exceeds human capabilities. To address this, the industry has developed 4D automatic annotation technology. Tesla utilizes the Dojo supercomputer and custom D1 chips to perform full 3D reconstruction of historical driving paths through offline reconstruction techniques (such as NeRF), generating extremely high-precision ground truth to supervise the training of online networks. This automatic annotation system can process data from 10,000 driving trips in just 12 hours, with an efficiency equivalent to 5 million hours of manual labor.
At the hardware level, running high-frame-rate occupancy networks requires an exceptionally powerful computational foundation. Tesla's FSD chip ensures real-time performance by distributing neural network execution across independent systems through distributed parallel computing. Manufacturers like Li Auto, on the other hand, adopt a dual NVIDIA Orin-X platform, providing a total computational power of up to 508 TOPS, offering ample margin for complex BEV fusion algorithms and comfort COST prediction models. This logic of 'trading computational power for spatial understanding' is the core driving force behind the current hardware competition in intelligent vehicles.
In the years ahead, the perception capabilities of autonomous driving systems will become increasingly fine - grained and generalized. The advent of high - quality 3D occupancy benchmark datasets, exemplified by OpenOcc, will drive continuous improvement in the algorithm's ability to detect small objects. Simultaneously, occupancy networks will transcend their current role of merely perceiving obstacles. They will progress towards semantic occupancy, enabling them not only to detect the presence of an object in front of the vehicle but also to discern whether it is grass, a puddle, or solid rock. This, in turn, will inform the vehicle's decision - making process on unpaved roads.
Final Thoughts
When we cast our minds back to the development trajectory of autonomous driving, we find ourselves in the midst of a transformative era, transitioning from 'image recognition' to 'spatial perception'. The occupancy network is far more than just a technological innovation; it represents the latest artificial intelligence solution for tackling real - world problems. To enable machines to drive in a manner akin to humans, the key lies in empowering them to develop the most intuitive and precise understanding of 'existence' and 'emptiness'. In this transformative journey, the occupancy network undoubtedly serves as the beacon that illuminates the path to 3D world perception, paving the way for the widespread adoption of autonomous driving.
-- END --
-
![]()
Enflame Tech's IPO Journey: Navigating Over 5.9 Billion Yuan in Losses and Soaring Debt in Q1 This Year
-
![]()
Trillion-Yuan Giant Li Shufu 'Streamlines': Could Levc Be the Casualty?
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'






